 华为小米自动驾驶Occupancy Network对决
华为小米自动驾驶Occupancy Network对决

2023年6月计算机视觉学术圈CVPR举办两场自动驾驶研讨会,一个是端到端自动驾驶研讨会 (End-to-End Autonomous Driving Workshop),另一个是视觉中心自动驾驶研讨会 (Vision-Centric Autonomous Driving Workshop)。由此又引出4项算法任务挑战赛,其中:
第一项是OpenLane Topology即开放路口车道线拓扑矢量化构建,第一名是旷视,第二名是轻舟智航,理想L6自动驾驶供应商。第三名则是美国AMD,第四名是美团。
第二项是在线高精度地图绘制,第一名是旷视的自动驾驶子公司迈驰智行,第二名是美国独立研究者,第三名是上海交通大学。第十名是广汽研究院。
第四项是nuPlan即自动驾驶规划,第一名是德国Tübingen大学,第二名是地平线,第三名是初创公司云骥智行。
第三项是最具价值的3D Occupancy network预测,也就是特斯拉带火的占用网络,共有149个团队参加比赛,其中不乏业内巨头,包括英伟达、小米、上汽、华为、海康威视。
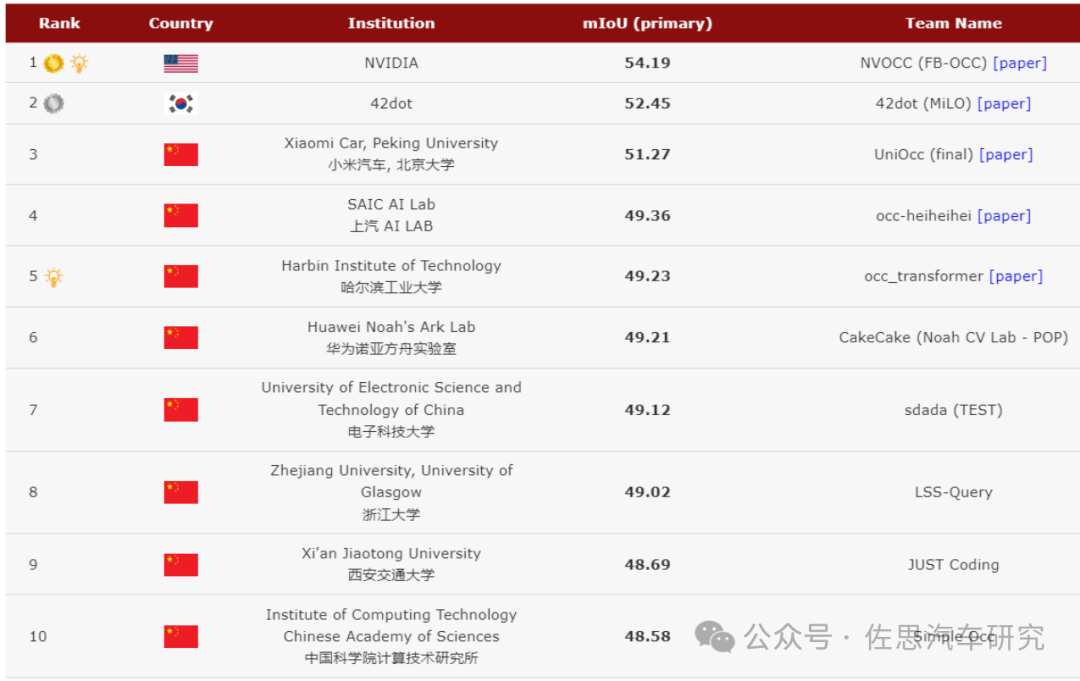
图片来源:https://opendrivelab.com/challenge2023/
占用网络挑战赛前10名,第一名有15000美元的奖金。第四名到第十名可算第三梯队,差距很小。英伟达遥遥领先。韩国自动驾驶初创公司42dot与小米可算第二梯队。
比赛中使用的Occ数据集来自nuScenes,要求选手在仅使用图像这个模态的情况下,对200x200x16的3D体素空间的占据情况进行预测,其中评价指标采用mIoU,并且将仅对图像中的可视范围中的预测结果进行评估。在比赛中,一共有两个Baseline可供选择,一个是官方提供的基于BEVFormer框架的实现,另一个则是基于BEVDet框架实现的,也分别代表了在3D目标检测现在主流的两个实现路线,LSS和Transformer。两种Baseline都将原来输入检测头的特征,从BEV空间拉伸成200x200x16的3D体素空间,然后接上一个简单的语义分割头,来对3D占据的结果进行预测。
第一名英伟达的FB-OCC,其成功的关键还是大模型,英伟达使用了比较新的InterImage-H来作为他们的Backbone,而为了更好的应用InterImage-H,作者还将其在原先在COCO的预训练基础上,在object365上也进行了预训练,使其更好的应用在此任务上。InternImage-H参数多达10.8亿个,当然大模型也不是想用就能用,太大的模型容易出现过拟合,且消耗运算和存储资源也较多。
最新2D图像骨干网对比
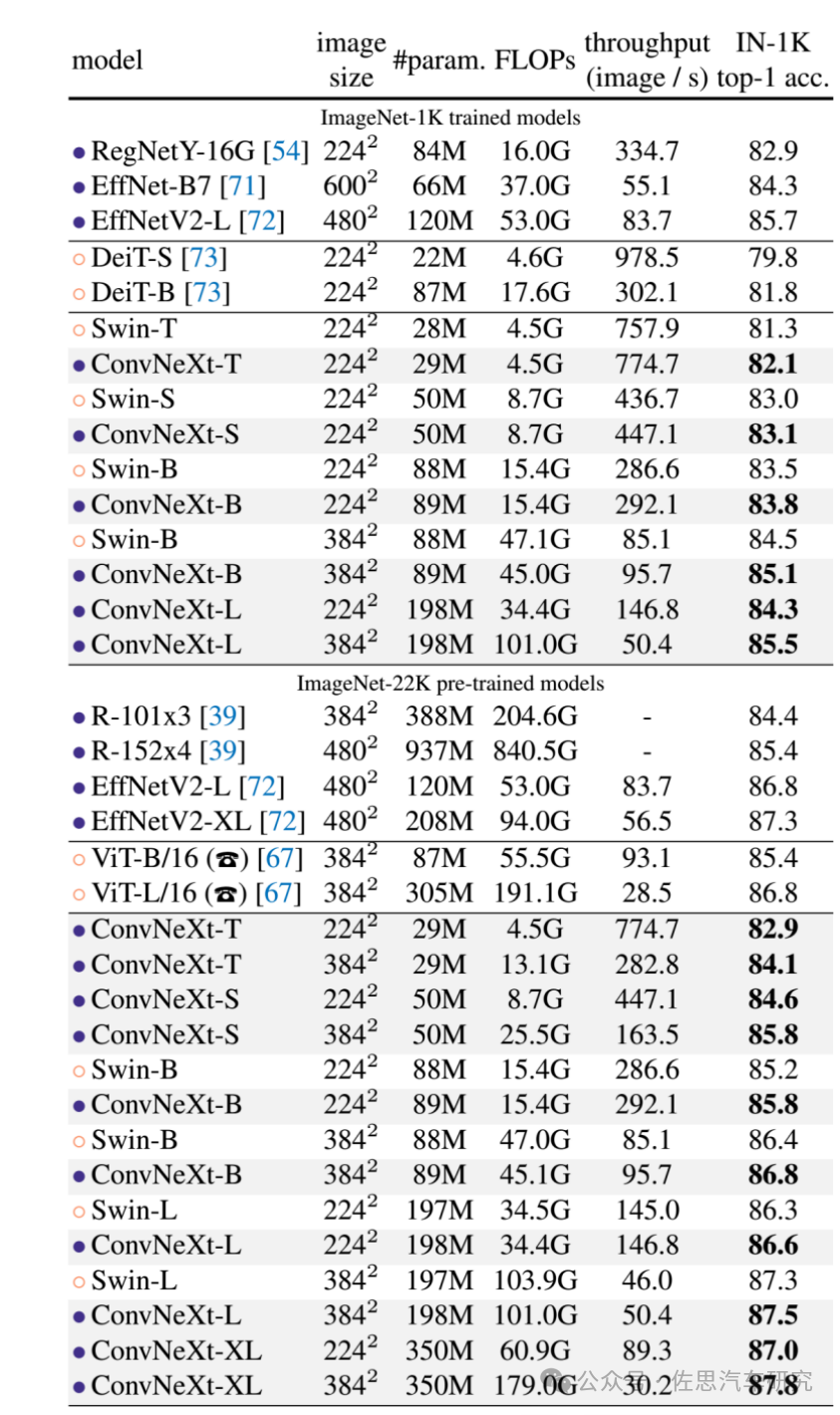
图片来源:arxiv.org
上表中,特斯拉使用META的RegNet,参数为8400万,消耗运算资源很少,得分82.9也算不低,小米UniOcc使用META的ConvNeXt-B,参数8900万,消耗运算资源最少,得分83.8,华为RadOcc使用微软的Swin-B,参数8800万,相对ConvNeXt-B消耗运算资源几乎翻倍,得分83.5,略高。得分最高的是ConvNeXt-XL,高达87.8,参数3.5亿个,消耗运算资源是Swin-B的十倍还多。
第二名是42dot,一家韩国初创公司,成功的关键也是大模型,其2D Backbone用了InterImage-XL,有3.35亿参数,3D Backbone用了微软的Swin-V2-L,有30亿参数,但提升不大。
重点来看第三名的小米汽车,论文题目为《UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering》,迄今为止在网上可以找到的小米汽车的三篇论文都是围绕Occupancy来展开的,足见小米对Occupancy的重视程度。
UniOcc框架
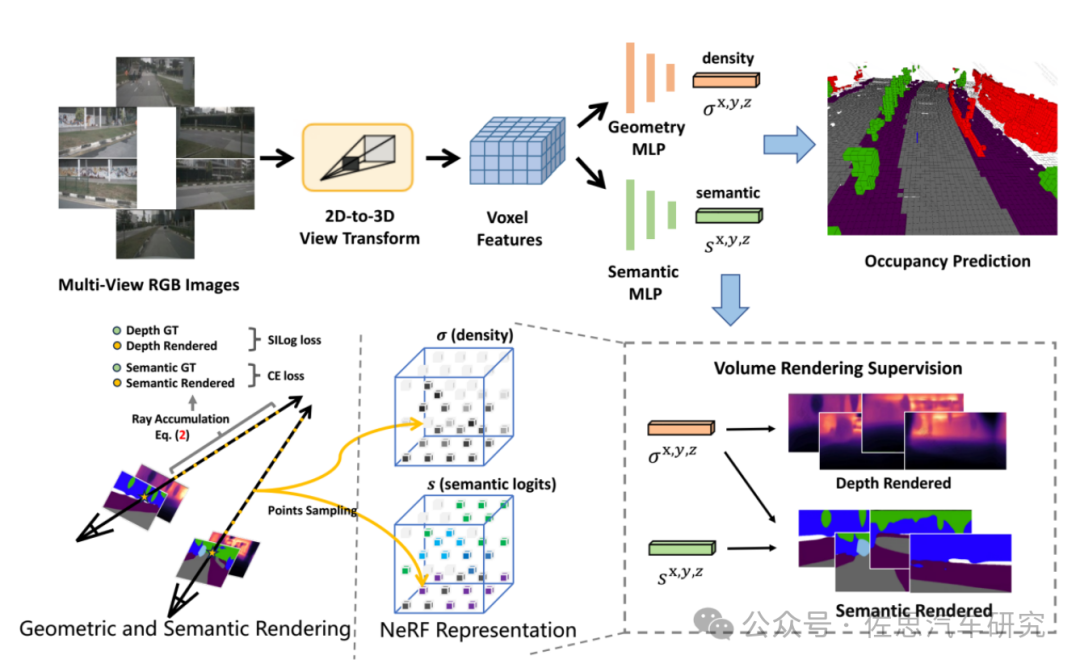
图片来源:《UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering》
小米和接下来要说到的华为都使用了比较新颖的知识蒸馏技术,即教师学生模型,这是一种半监督深度学习方式,最早由谷歌提出,发布于2015年3月,论文为《Distilling the Knowledge in a Neural Network》。知识蒸馏技术是一种模型压缩方法,是一种基于Teacher-Student模型的训练方法。知识蒸馏(Knowledge Distillation),顾名思义就是将一个复杂的大模型的“知识”,蒸馏到一个简单的小模型中,比较类似于教师(大模型)向学生(小模型)传授(蒸馏)知识。这样做主要是因为大模型部署起来成本惊人,通常最低都是8张英伟达A100这样的计算和存储资源,成本最低也在5万美元以上,在车上完全不可能部署大模型,必须采用蒸馏模式。在Teacher-Student模型中通常有两个阶段:
① 教师模型训练:首先训练一个较大或复杂的教师模型,它通常具有更多的参数和复杂性,并能够在训练数据上表现得更好。
② 学生模型训练:接着,使用教师模型的输出作为辅助目标,指导较简化的学生模型进行训练。学生模型尝试去模仿教师模型的预测结果,以此来学习教师模型的“知识”。在训练学生模型时,通常会利用教师模型的软标签(soft labels)或教师模型的隐藏层表示(logits)作为额外的监督信号,结合有标签数据进行训练。这个过程中,学生模型的目标是尽量拟合教师模型的预测结果,并同时拟合真实的标签信息。
有些外行把软标签(标注,标记)说成是无标签,说什么自动驾驶数据集完全不需要标签了,这当然是大错特错,绝对的无标签无监督深度学习永远不可能实现,顶多是半监督,硬标签是1或者0,没有中间状态,软标签则是连续分布的概率。软标签可以用教师模型的SOFTMAX层输出的类别概率做为软标签,某种意义上这可算是自动生成的标签,无需人工添加。教师模型还是需要标签数据,还是需要人工标注。
小米的创新有三点,一是使用NeRF的体渲染(volume rendering)来统一2D和3D表示监督的通用解决方案,二是通过知识蒸馏做深度预测训练,三是用低成本的体渲染监督学习代替成本高昂稀缺的3D占用网络语义标签监督学习。
NeRF神经辐射场,不同于传统的三维重建方法把场景表示为点云、网格、体素等显式的表达,它独辟蹊径,将场景建模成一个连续的5D辐射场隐式存储在神经网络中,只需输入稀疏的多角度带pose的图像训练得到一个神经辐射场模型,根据这个模型可以渲染出任意视角下的清晰的照片。通俗来讲就是构造一个隐式的渲染流程,其输入是某个视角下发射的光线的位置o,方向d以及对应的坐标(x,y,z),送入神经辐射场Fθ得到体密度和颜色,最后再通过体渲染得到最终的图像。显式是离散的表达,不能精细化,导致重叠等伪影,耗费内存,限制了在高分辨率场景的应用。隐式是连续的表达,能够适用于大分辨率的场景,而且不需要3D信号进行监督。
NeRF需要两个MLP,一个负责 Coarse,一个负责 Fine,因此计算量比较大,存储资源要求也比较高。自动驾驶领域使用NeRF还是相当少见的,因为它太消耗运算和存储资源了,同时自动驾驶的视角有限,一般是5个视角,想做好NeRF相当困难。
小米的知识蒸馏DTS框架
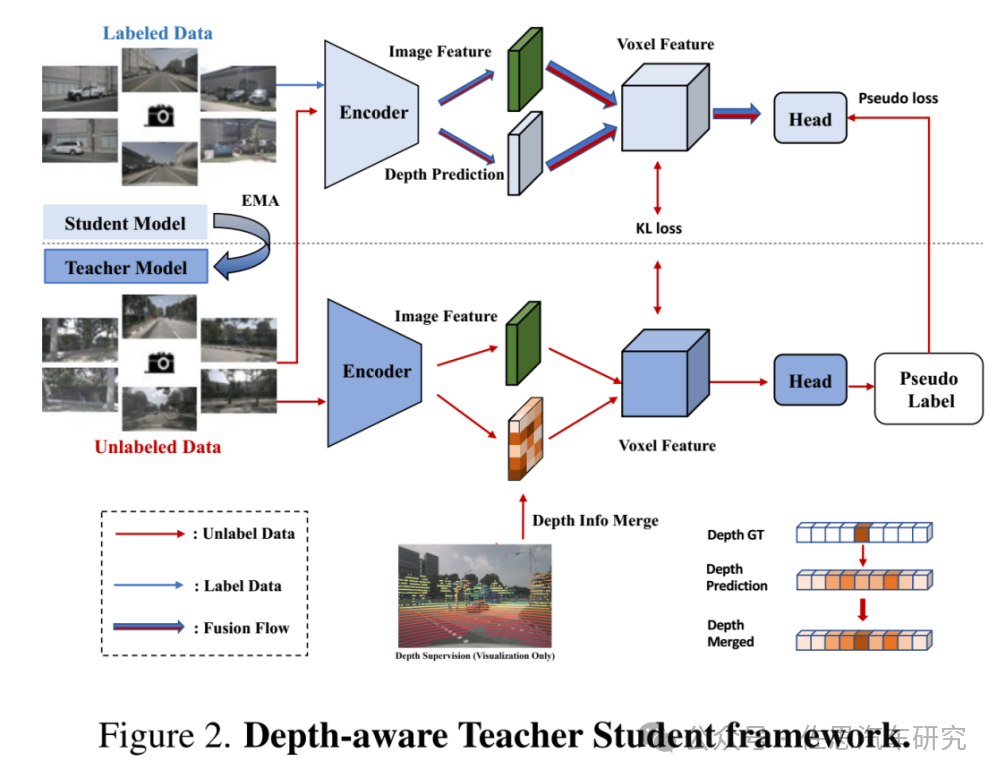
图片来源:《UniOcc: Unifying Vision-Centric 3D Occupancy Prediction with Geometric and Semantic Rendering》
小米的知识蒸馏DTS框架,在训练中使用visible masks,使用更强的预先训练的骨干,增加体素分辨率,以及实现Test-Time Augmentation(TTA)。大部分人都是使用英伟达的LSS算法获得深度,小米的DTS可谓独树一帜。
第四名来自上汽AI LAB,其整体框架设计采用BEVDet的设计思路,主要提出利用多尺度信息来进行训练和预测以及一种解耦头的预测方法。论文异常简单,只有4页。
上汽OCC架构
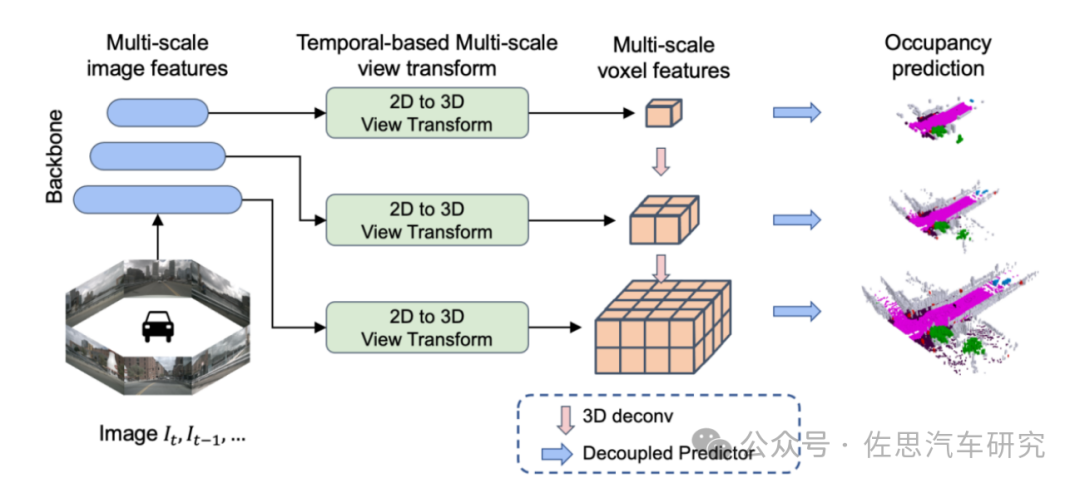
图片来源:上汽
最后来看华为的,华为由华为诺亚方舟实验室出面,诺亚方舟实验室是华为三级部门,隶属于中央研究院。内地主要分布在北京、深圳、上海、西安。下面又分成很多组,比如计算视觉、终端视觉、自动驾驶、网络大脑、NLP等等。主要的工作内容就是科研和落地,主要做前沿研究,之所以取名诺亚方舟就是说当华为出现大洪水那样级别的灾难时,诺亚方舟实验室的成果足以让华为走出困境。
最初华为诺亚方舟并未提供论文,直到2023年底才提供论文,论文题目《RadOcc: Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation》华为论文换了Occ3D的测试数据集,最好成绩高达55.09,比第一名英伟达还高,当然不是一个测试数据集,没办法直接对比,但华为应该在挑战赛后还是做了不少改进的地方。
华为也是采用知识蒸馏的教师学生模式。
华为RadOcc架构
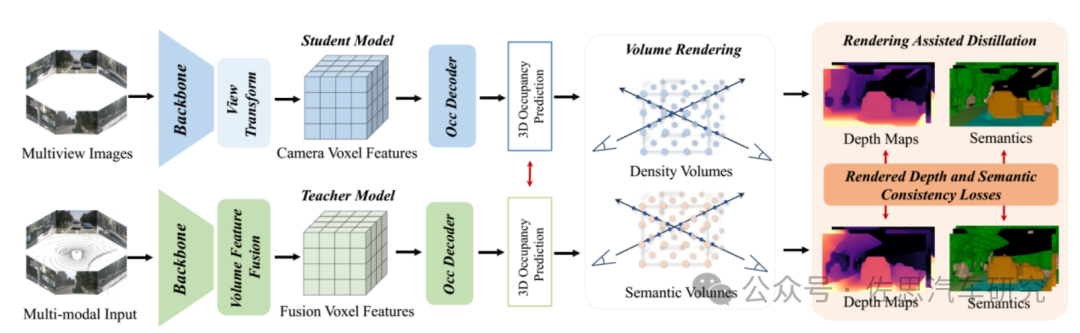
图片来源:《RadOcc: Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation》
华为RadOcc架构,思路和小米基本一致,也用了NeRF。教师网络是多模态模型,而学生网络仅需要相机输入,无需激光雷达。两个网络的预测将用于通过可微分体渲染(differentiable volume rendering)生成渲染深度和语义。
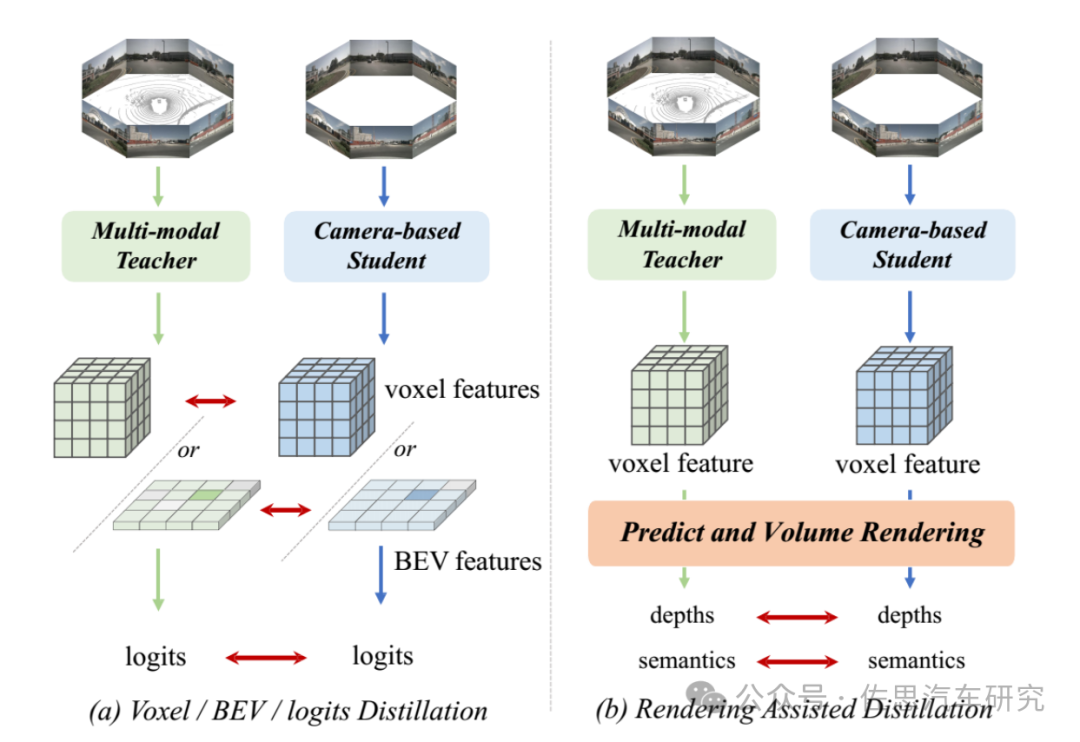
图片来源:《RadOcc: Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation》
现有的方法如图a的是将特征或 logits 进行对齐。RadOcc的核心思想是对教师模型和学生模型生成的渲染结果进行对齐,如图(b)所示。使用相机的内参和外参对体素特征进行体渲染Volume Rendering,能够从不同的视点获得相应的深度图和语义图。为了实现渲染输出之间更好的对齐,引入了新颖的渲染深度一致性(RDC)和渲染语义一致性(RSC)损失。一方面,RDC 损失强制光线分布(ray distribution)的一致性,这使得学生模型能够捕获数据的底层结构。另一方面,RSC损失利用了视觉基础模型的优势,并利用预先提取的segment进行affinity蒸馏。允许模型学习和比较不同图像区域的语义表示,从而增强其捕获细粒度细节的能力。
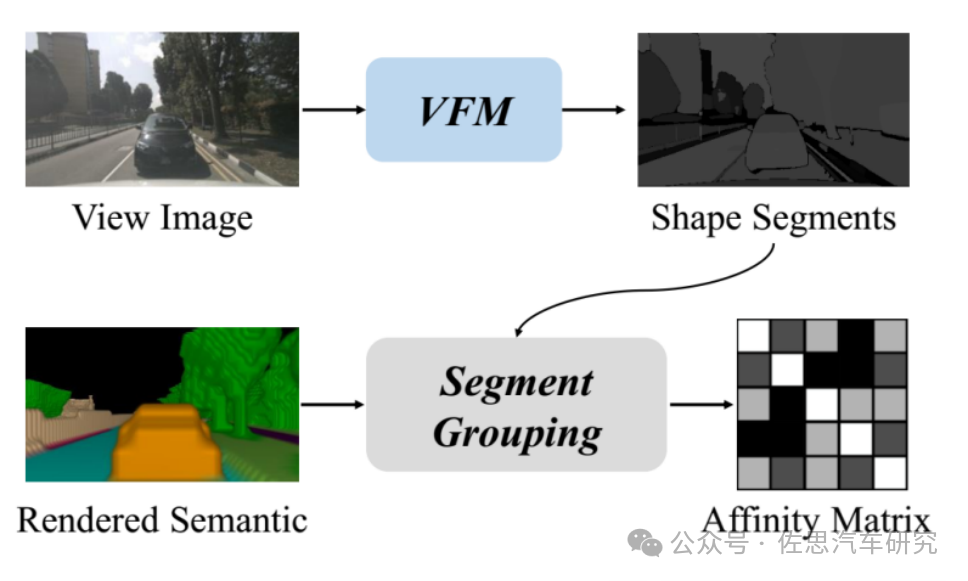
图片来源:《RadOcc: Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation》
采用视觉基础模型(VFM),即SAM,将segments提取到原始图像中。对每个segment 中渲染的语义特征进行segment聚合,获得affinity matrix 。
自动驾驶的理论基础或者说骨干被META、谷歌、英伟达和微软这些巨头垄断,自动驾驶算法公司能做的就是应用层的微调,大家的技术水平都差不多。另一方面理论基础在没有实现重大突破之前,自动驾驶难有实质性进展。
审核编辑:刘清
-
华为
+关注
关注
216文章
35260浏览量
256551 -
小米
+关注
关注
70文章
14476浏览量
147945 -
自动驾驶
+关注
关注
790文章
14367浏览量
171162 -
大模型
+关注
关注
2文章
3193浏览量
4154
原文标题:华为小米对决自动驾驶Occupancy Network
文章出处:【微信号:zuosiqiche,微信公众号:佐思汽车研究】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
卡车、矿车的自动驾驶和乘用车的自动驾驶在技术要求上有何不同?
华为数据中心自动驾驶网络通过EANTC欧洲高级网络测试中心L4级自智网络测评

自动驾驶安全基石:ODD

华为受邀出席第一届自动驾驶产业发展论坛
从《自动驾驶地图数据规范》聊高精地图在自动驾驶中的重要性
一文聊聊自动驾驶测试技术的挑战与创新

华为宋晓迪出席自动驾驶网络峰会
自动驾驶汽车安全吗?

智能驾驶与自动驾驶的关系

自动驾驶技术的典型应用 自动驾驶技术涉及到哪些技术








 工商网监
工商网监
评论