 幻觉降低30%!首个多模态大模型幻觉修正工作Woodpecker
幻觉降低30%!首个多模态大模型幻觉修正工作Woodpecker


图中体现了两种幻觉,红色部分错误地描述了狗的颜色(属性幻觉),蓝色部分描述了图中实际不存在的事物(目标幻觉)。幻觉对模型的可靠性产生了显著的负面影响,因此引起了许多研究者的重视。
以往的方法主要集中在 MLLM 本身,通过在训练数据以及架构上进行改进,以重新微调的方式训练一个新的 MLLM。这种方式会造成较大的数据构建和训练开销,且较难推广到各种已有的 MLLMs。
近日,来自中科大等机构的研究者们提出了一种免训练的即插即用的通用架构“啄木鸟(Woodpecker)”,通过修正的方式解决 MLLM 输出幻觉的问题。

论文链接:
https://arxiv.org/pdf/2310.16045.pdf
代码链接:
https://github.com/BradyFU/Woodpecker
Woodpecker 可以修正各种场景下模型输出的幻觉,并输出检测框作为引证,表明相应的目标确实存在。例如,面对描述任务,Woodpecker 可以修正其中带有幻觉的部分。

对于 MLLM 难以检测到的小对象,Woodpecker 也可以精准修正:

面对 MLLM 难以解决的复杂的计数场景,Woodpecker 同样可以进行解决:

对于目标属性类的幻觉问题,Woopecker 处理地也很好:

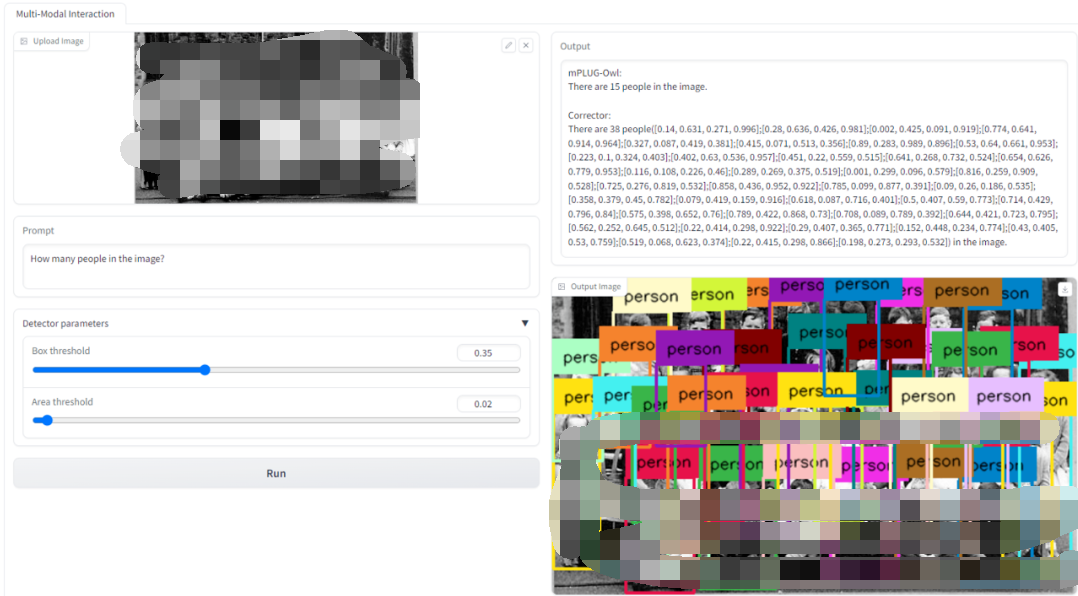
我们还提供了 Demo 供读者测试使用,如下图所示,上传图片并输入请求,就可以得到修正前以及修正后的模型答复,以及供参考验证的新图片。

方法
Woodpecker 的架构如下,它包括五个主要步骤:关键概念提取、问题构造、视觉知识检验、视觉断言生成以及幻觉修正。

关键概念提取:关键概念指的是 MLLM 的输出中最可能存在幻觉的存在性目标,例如上图描述中的“自行车;垃圾桶;人”。我们可以 Prompt 大语言模型来提取出这些关键概念,这些关键概念是后续步骤进行的基础;
问题构造:围绕着前一步提取出的关键概念,Prompt 大语言模型来提出一些有助于检验图片描述真伪的问题,如“图中有几辆自行车?”、“垃圾桶边上的是什么?”等等;
视觉知识检验:使用视觉基础模型对提出的问题进行检验,获得与图片以及描述文本相关的信息。例如,我们可以利用 GroundingDINO 来进行目标检测,确定关键目标是否存在以及关键目标的数量。这里我们认为像 GroundingDINO 这类视觉基础模型对图片的感知能力比 MLLM 本身的感知能力更强。对于目标颜色等这类属性问题,我们可以利用 BLIP-2 来进行回答。BLIP-2这类传统 VQA 模型输出答案的长度有限,幻觉问题也更少;
视觉断言生成:基于前两步中获得的问题以及对应的视觉信息,合成结构化的“视觉断言”。这些视觉断言可以看做与原有 MLLM 的回答以及输入图片相关的视觉知识库;
幻觉修正:基于前面得到的,使用大语言模型对 MLLM 的文本输出进行逐一修正,并提供目标对应的检测框信息作为视觉检验的参照。
 ?
?实验效果
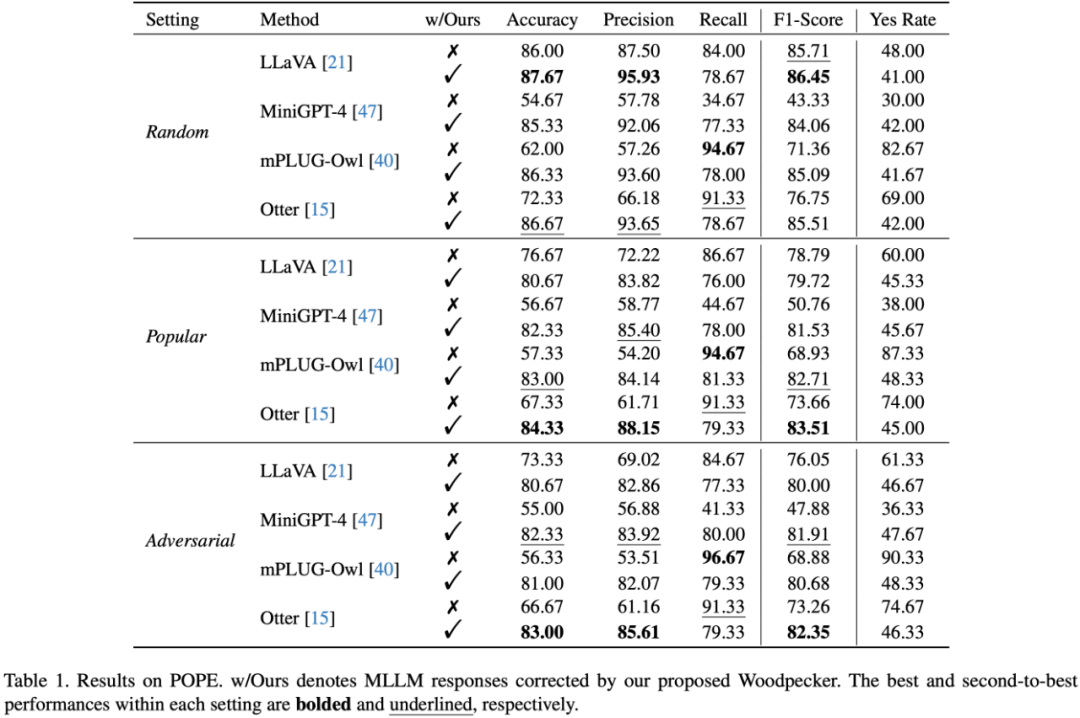
实验选取了几个典型的 MLLM 作为基线,包括:LLaVA,mPLUG-Owl,Otter,MiniGPT-4 论文中首先测试了 Woodpecker 在面对目标幻觉时的修正能力,在 POPE 验证集的实验结果如下表所示:
此外,研究者还应用更全面的验证集 MME,进一步测试 Woodpecker 在面对属性幻觉时的修正能力,结果如下表所示:
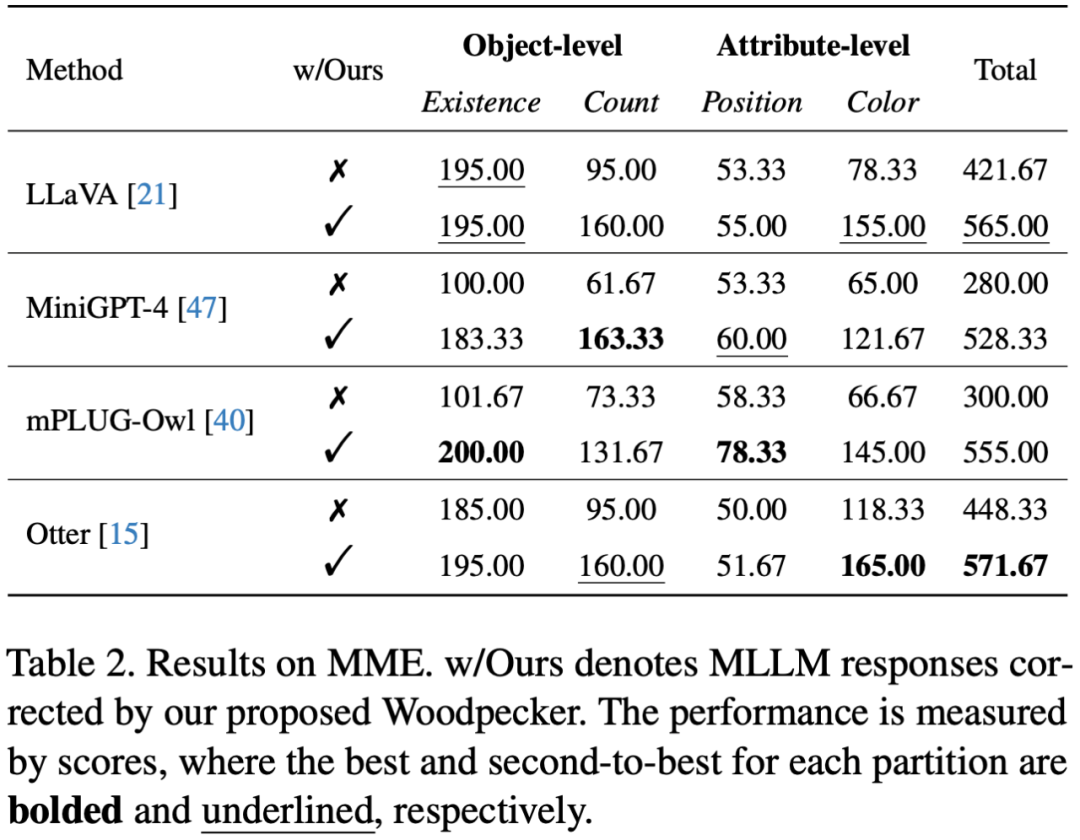
从表中可见 Woodpecker 不仅在应对目标幻觉时有效,在修正颜色等属性幻觉时也具有出色的表现。LLaVA 的颜色得分从 78.33 分大幅提升到 155 分!经过 Woodpecker 修正后,四个基线模型在四个测试子集上的总分均超过 500 分,在总体感知能力上获得了显著提升。
为了更直接地衡量修正表现,更直接的方式是使用开放评测。不同于以往将图片转译后送入纯文本 GPT-4 的做法,文章利用 OpenAI 最近开放的视觉接口,提出使用 GPT-4 (Vision) 对修正前后的图片描述直接对下列两个维度进行打分:- 准确度:模型的答复相对于图片内容是否准确
-
详细程度:模型答复的细节丰富度
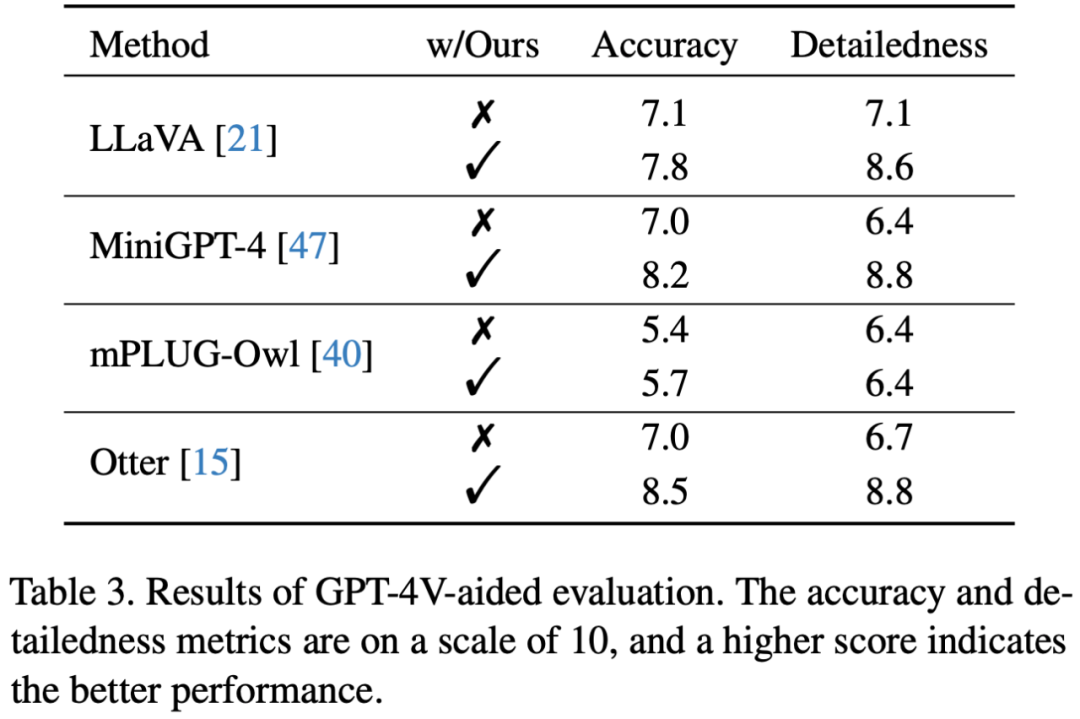
结果表明经过 Woodpecker 修正后图片描述的准确性有一定的提升,这说明该框架可以有效修正描述中幻视的部分。另一方面,Woodpecker 修正后引入的定位信息丰富了文本描述,提供了进一步的位置信息,从而提升了细节丰富度。GPT-4V 辅助的评测样例如下图所示:

·
-
物联网
+关注
关注
2932文章
46349浏览量
394258
原文标题:幻觉降低30%!首个多模态大模型幻觉修正工作Woodpecker
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
AI智能体+AIoT:智能时代的关键联结,还是又一场幻觉与泡沫?

商汤日日新SenseNova融合模态大模型 国内首家获得最高评级的大模型
爱芯通元NPU适配Qwen2.5-VL-3B视觉多模态大模型

海康威视发布多模态大模型AI融合巡检超脑
利用腾讯ima收藏公众号推文构建个人知识库,拒绝AI幻觉

【「基于大模型的RAG应用开发与优化」阅读体验】+第一章初体验

商汤日日新多模态大模型权威评测第一
名单公布!【书籍评测活动NO.52】基于大模型的RAG应用开发与优化
一文理解多模态大语言模型——下






 工商网监
工商网监
评论