 NVIDIA为加速生成式AI而设计的超级芯片全面投产
NVIDIA为加速生成式AI而设计的超级芯片全面投产

2023年是大语言模型、生成式AI、ChatGPT、AIGC大爆发的一年。GPU是大规模深度学习、高性能计算的重要硬件基础,而大语言模型,如生成式AI、ChatGPT等,则借助GPU的计算能力快速地训练和推理,获得更高的模型效果和更广泛的应用场景。尤其在游戏开发领域,运用大语言模型可以加强游戏的情节推进、人工智能角色表现等方面的体验,而加速训练的英伟达GPU则可以使这些特征更加流畅。由于英伟达在GPU硬件设计和优化方面的领先地位,为大型语言模型的快速发展提供了扎实的技术基础。
目前中国和美国研发的大型AI模型数量占全球总数的80%以上,中国排名全球第二,仅次于美国,其中,已经发布超过79个10亿参数规模以上的大型AI模型。中国科学技术信息研究所所长、科技部新一代人工智能发展研究中心主任赵志耘表示,我国前期在人工智能领域的各项部署,为大模型发展奠定了坚实的基础,并已经建立起涵盖理论方法和软硬件技术的体系化研发能力,形成了紧跟世界前沿的大模型技术群。
目前,我国参数规模在10亿以上的大型AI模型数量达到79个,并且地域和领域分布相对于集中,全国14个省市/地区都在开展大模型研发,主要集中在北京和广东两地,其中北京28个,广东22个。同时,大模型应用也在不断拓展和深化落地。一方面,通用领域大模型如文心一言、通义千问、紫东太初、星火认知等正在快速发展,打造跨行业通用化人工智能能力平台,其应用行业在办公、生活、娱乐向医疗、工业、教育等加速渗透;另一方面,针对生物制药、遥感、气象等垂直领域的专用大模型,发挥其领域纵深优势,提供针对特定业务场景的高质量专业化解决方案。
5月29日,英伟达在2023台北电脑展大会推出了DGX GH200 AI超级计算机,这是配备256颗Grace Hopper超级芯片和NVIDIA NVLink交换机系统的尖端系统,具有1 exaflop性能和144TB共享内存。该超级计算机的推出,在人工智能领域引起了轰动,标志着英伟达在大型AI模型技术和硬件设计领域的再次领先。其强大的计算和网络技术,为生成式AI、大型语言模型和推荐系统的应用和开发带来了更广阔的前景,进一步拓展了AI的边界。此外,DGX GH200还是第一台Grace Hopper超级芯片和NVLink交换机系统配对的超级计算机,其带宽较之前显卡相比多48倍,为人工智能先驱和云服务提供商打开了探索新领域的大门。
DGX GH200与生成式AI
英伟达发布了一系列面向生成式AI的产品和服务,包括大内存生成式AI超级计算机DGX GH200、Grace Hopper超级芯片GH200的全面投产、全新加速以太网平台Spectrum-X、定制化AI模型代工服务、与WPP合作打造生成式AI内容引擎等,多项举措都为生成式AI的应用与发展提供了更广阔的前景。
此外,英伟达还发布了MGX服务器规范,并且已有1600多家生成式AI公司采用了英伟达技术。
目前,英伟达市值已经达到9632亿美元,仅差一步之遥即可加入“万亿市值俱乐部”,成为美国上市公司市值排名第五的企业和第一家由华人创立的万亿美元市值公司。
E级算力,谷歌云、Meta、微软首批试用
英伟达日前发布了一款采用最新GPU和CPU的系统巅峰之作——新型大内存AI超级计算机DGX GH200,预计于今年年底上市。
该超算旨在支持生成式AI语言应用、推荐系统和数据分析工作负载的大型下一代模型。DGX GH200集成了先进的加速计算和网络技术,是首款将Grace Hopper超级芯片与英伟达NVLink Switch系统搭配的超级计算机。
采用新互连方式,256个Grace Hopper超级芯片可以像单个巨型GPU一样协同运行,提供了1EFLOPS性能和144TB共享内存,比上一代DGX A100 320GB系统的内存多出近500倍。
谷歌云、Meta、微软等是首批获得访问权限的公司,英伟达打算将DGX GH200设计蓝图提供给其他云服务商及超大规模计算厂商,以便他们进一步为其基础设施定制DGX GH200。
英伟达还正在打造自己的基于DGX GH200的大型AI超级计算机NVIDIA Helios,将于今年年底上线。此外,DGX GH200超级计算机包含英伟达软件,提供AI工作流管理、企业级集群管理、加速计算、存储和网络基础设施库,以及100多个框架、预训练模型和开发工具,以简化AI生产的开发和部署。
英伟达的Base Command软件可以帮助管理AI工作流程、企业级集群、加速计算和存储、网络基础设施等,而AI Enterprise软件层则提供了许多框架、预训练模型和开发工具,以简化AI生产的开发和部署。DGX GH200超级计算机的推出将有助于推动AI技术的发展,为各行各业提供更快、更强大的AI计算能力,加速AI技术的应用和落地。
GH200芯片全面投产
英伟达日前宣布,已全面投产GH200 Grace Hopper超级芯片,将为AI和高性能计算工作负载提供动力。
基于GH200的系统已经被全球制造商采用,提供了超过400个配置,这些系统都基于英伟达的最新Grace Hopper和Ada Lovelace架构。
GH200 Grace Hopper超级芯片采用了NVIDIA NVLink-C2C互连技术,将英伟达Grace CPU和Hopper GPU架构组合在同一封装中,提供高达900GB/s的总带宽,比传统加速系统中的标准PCIe Gen5通道带宽高7倍,同时互连功耗降低到原来的1/5,能够满足苛刻的生成式AI和高性能计算(HPC)应用。预计几家全球超大规模计算企业和超算中心客户将采用GH200驱动的系统,这些系统将于今年晚些时候上市。
打造数亿美元生成式AI超算
此外,黄仁勋还宣布推出NVIDIA Spectrum-X平台,旨在提高基于以太网的AI云的性能和效率。
Spectrum-X基于网络创新,将英伟达Spectrum-4交换机和BlueField-3 DPU紧密耦合,实现了1.7倍的整体AI性能和能效提升,并通过性能隔离增强了多租户功能,保持一致和可预测的性能。
Spectrum-X具有高度通用性,能够用于各种AI应用,与基于以太网的堆栈互操作,支持开发者构建软件定义的云原生AI应用程序。全球各大云计算提供商正在采用Spectrum-X平台扩展生成式AI服务。Spectrum-X、Spectrum-4交换机、BlueField-3 DPU等现已在戴尔、联想、超微等系统制造商处提供。
NVIDIA正在以色列数据中心构建一台超大规模生成式AI超级计算机Israel-1作为Spectrum-X参考设计的蓝图和测试平台。该超算将采用戴尔PowerEdge XE9680服务器、英伟达HGX H100超级计算平台、内置BlueField-3 DPU和Spectrum-4交换机的Spectrum-X平台,预计价值数亿美元。该平台支持256个200Gb/s端口通过单个交换机连接,或在两层leaf-spine拓扑中提供16000个端口,以支持AI云的增长和扩展,同时保持高水平的性能并最大限度地减少网络延迟。
全球领先的云计算提供商正在采用Spectrum-X平台扩展生成式AI服务。Spectrum-X、Spectrum-4交换机、BlueField-3 DPU等现已在戴尔、联想、超微等系统制造商处提供。
MGX服务器规范
模块化参考架构
黄仁勋同时发布了NVIDIA MGX服务器规范,为系统制造商提供了模块化参考架构,以适应广泛的AI、HPC及NVIDIA Omniverse应用。
MGX支持英伟达全系列GPU、CPU、DPU和网络适配器,以及各种x86及Arm处理器,这使得制造商能够更有效地满足每个客户的独特预算、电力输送、热设计和机械要求。
永擎(ASRock Rack)、华硕(ASUS)、技嘉(GIGABYTE)、和硕(Pegatron)、QCT、超微(Supermicro)等将采用MGX构建下一代加速计算机,可将开发成本削减多达3/4,并将开发时间缩短2/3至仅需6个月。MGX可以从为其服务器机箱加速计算优化的基本系统架构开始,然后选择GPU、DPU和CPU。同时,MGX提供了英伟达产品灵活的多代兼容性,以确保制造商可以重用现有设计并轻松采用下一代产品。MGX还能轻松集成到云和企业数据中心中。
除了MGX规范外,黄仁勋还宣布,英伟达与日本电信巨头软银合作,在日本建立一个分布式数据中心网络。该网络将在一个共同的云平台上提供5G服务和生成式AI应用。数据中心将使用MGX系列(包括Grace Hopper、BlueField-3 DPU和Spectrum以太网交换机)以提供5G协议所需的高精度定时,并提高频谱效率以降低成本和能耗。
这些系统有助于探索自动驾驶、AI工厂、AR/VR、计算机视觉和数字孪生等领域的应用。未来的用途可能包括3D视频会议和全息通信。这将为这些领域提供更高效、更灵活和更先进的解决方案,推动技术和产业的发展。
GH200在游戏行业的应用
黄仁勋在宣布推出针对游戏的Avatar云引擎(ACE)服务,这是一项定制AI模型代工服务,中间件、工具和游戏开发者可以使用它来构建和部署定制的语音、对话和动画AI模型。
ACE能赋予非玩家角色(NPC)更智能且不断进化的对话技能,使其能够以栩栩如生的个性来回答玩家的问题。ACE for Games为语音、对话和角色动画提供了优化的AI基础模型,包括:英伟达NeMo,使用专有数据,构建、定制和部署语言模型;英伟达Riva,用于自动语音识别和文本转语音,以实现实时语音对话;英伟达Omniverse Audio2Face,用于即时创建游戏角色的表情动画,以匹配任何语音轨道。
此外,英伟达与其子公司Convai合作,展示了如何快速用英伟达ACE for Games来构建游戏NPU。在名为“Kairos”的演示中,英伟达展示了一个与一个拉面店的供应商Jin互动的游戏。基于生成式AI,Jin虽是个NPC,却能拟真地回答自然语言问题,且回答内容与叙述的背景故事一致。开发人员可以集成整个NVIDIA ACE for Games解决方案,也可以只使用他们需要的组件。多家游戏开发商和初创公司已采用英伟达的生成式AI技术。
黄仁勋还介绍了英伟达和微软如何在生成式AI时代合作推动Windows PC的创新。新的和增强的工具、框架和驱动程序使PC开发者更容易开发和部署AI,例如用于优化和部署GPU加速AI模型和新图形驱动程序的微软Olive工具链将提高带有英伟达GPU的Windows PC上的DirectML性能。此次合作将增强和扩展搭载RTX GPU的1亿台PC的安装基础,可提升400多个AI加速的Windows应用程序和游戏的性能。这将为PC游戏带来更高的性能和更好的体验,同时也将推动AI在Windows PC上的应用和发展。
总的来说,黄仁勋在宣布中介绍了NVIDIA在游戏AI方面的最新进展和合作,包括Avatar云引擎(ACE)服务、微软合作推动Windows PC的创新等。这些技术和合作将为游戏开发者带来更多的AI工具和解决方案,为玩家带来更好的游戏体验。
DGX GH200在数字广告中的应用
英伟达的生成式AI技术也将在数字广告行业带来新机遇。基于NVIDIA AI和Omniverse技术的引擎将多个创意3D和AI工具连接在一起,以大规模革新商业内容和体验。
英国WPP集团,全球最大的营销服务机构,正与英伟达合作,利用Omniverse Cloud构建首个生成式AI内容引擎,以更高效和高质量的方式为客户创建商业内容。
新引擎连接了来自Adobe和Getty Images等工具的3D设计、制造和创意供应链工具的生态系统。黄仁勋在演讲中展示了创意团队如何将他们的3D设计工具连接在一起,并在Omniverse中构建客户产品的数字孪生。使用负责任的数据来源训练生成式AI技术并结合英伟达Picasso一起构建,使其能够快速生成虚拟集。此后,WPP客户可利用完整的场景生成大量广告、视频和3D体验,供全球市场和用户在任何网络设备上使用。
这项合作在数字广告领域持续推动着生成式AI技术的发展。WPP首席执行官马克·里德表示,生成式AI技术正在以惊人的速度改变营销世界,合作所提供的独特竞争优势将改变品牌为商业用途创建内容的方式,并巩固WPP在为世界顶级品牌创造性应用AI方面的行业领导地位。
DGX GH200在
电子制造商中的应用
全球电子制造商正在使用一种全新的综合参考工作流程,这种工作流程结合了英伟达的多种技术,包括生成式AI、3D协作、仿真和自主机器,旨在帮助制造商规划、构建、运营和优化他们的工厂。这些技术包括英伟达的Omniverse,它连接了顶级计算机辅助设计和生成式AI的API和前沿框架;英伟达的Isaac Sim应用程序,用于模拟和测试机器人;英伟达的Metropolis视觉AI框架,用于自动光学检测。
英伟达使电子制造商能够轻松构建和运营虚拟工厂,将其制造和检验工作流程数字化,并大大提高质量和安全,减少代价高昂的最后一刻意外和延误。黄仁勋在现场展示了一个完全数字化的智能工厂的演示。
富士康工业互联网、宜鼎国际、和硕、广达和纬创正在使用英伟达的参考工作流程,以优化他们的工作单元和装配线运营,同时降低生产成本,具体用例包括电路板质保检测点自动化、光学检测自动化、建设虚拟工厂、模拟协作机器人、构建及运营数字孪生等。
英伟达正在与几家领先的制造工具和服务提供商合作,构建一个全栈、单一的架构,每个架构都适用于每个工作流程级别。
在系统层面,英伟达IGX Orin提供了一个一体化的边缘AI平台,将工业级硬件与企业级软件和支持相结合。IGX满足边缘计算独特的耐用性和低功耗要求,同时提供开发和运行AI应用程序所需的高性能。其制造商合作伙伴们正在开发IGX驱动的系统,以服务于工业和医疗市场。
在平台层面,Omniverse连接了世界领先的3D、模拟和生成式AI提供商,团队可在他们最喜欢的应用程序之间构建互操作性,比如来自Adobe、Autodesk和Siemens的应用程序。
这些技术的整合使得制造商能够在一个统一的平台上进行设计、仿真、测试和生产,从而大大提高效率和质量。此外,英伟达还提供了一系列工具和服务,帮助制造商管理和优化他们的生产线,包括实时监控、数据分析和预测性维护。
英伟达的数字化工厂解决方案不仅适用于电子制造业,还可以应用于其他行业,如汽车制造、航空航天、医疗设备等。这些行业都需要高度自动化和数字化的生产线,以满足不断增长的市场需求和质量标准。
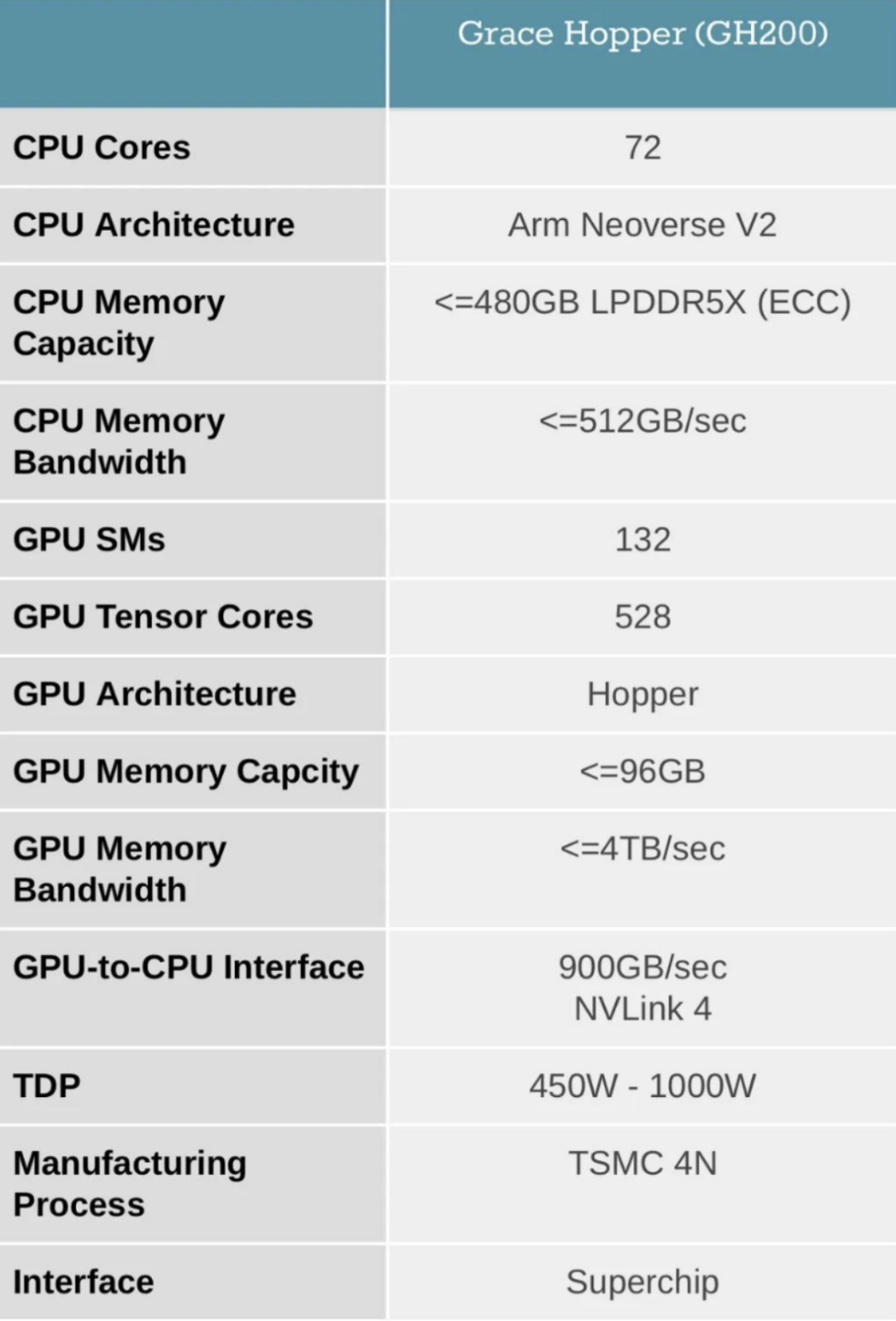
GH200产品参数
GH200是英伟达推出的最新超级计算机,最多可以放置256个GPU,适用于超大型AI模型的部署。相比之前的DGX服务器,GH200提供线性拓展方式和更高的GPU共享内存编程模型,可通过NVLink高速访问144TB内存,是上一代DGX的500倍。其架构提供的NVLink带宽是上一代的48倍,使得千亿或万亿参数以上的大模型能够在一台DGX内放置,进一步提高模型效率和多模态模型的开发进程。
GPU的统一内存编程模型一直是复杂加速计算应用取得突破的基石。NVIDIA Grace Hopper Superchip与NVLink开关系统配对,在NVIDIA DGX GH200系统中整合了256个GPU,通过NVLink高速访问144TB内存。与单个NVIDIA DGX A100 320 GB系统相比,NVIDIA DGX GH200为GPU共享内存编程模型提供了近500倍的内存,是突破GPU通过NVLink访问内存的100TB障碍的第一台超级计算机。NVIDIA Base Command的快速部署和简化系统管理使用户能够更快地进行加速计算。
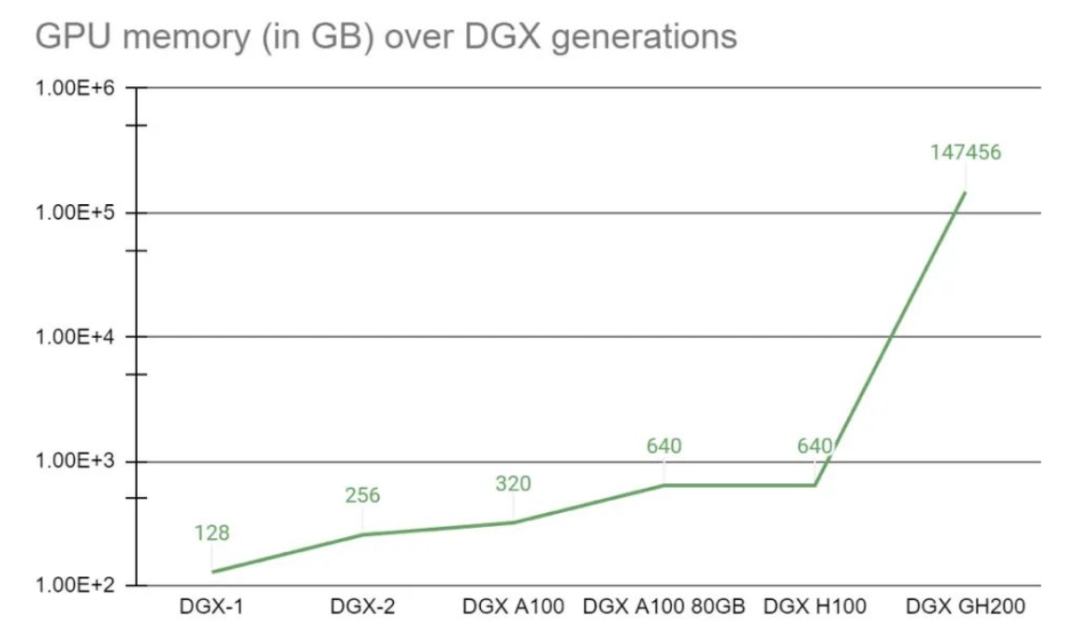
NVIDIA DGX GH200系统采用了NVIDIA Grace Hopper Superchip和NVLink Switch System作为其构建块。NVIDIA Grace Hopper Superchip将CPU和GPU结合在一起,使用NVIDIA NVLink-C2C技术提供一致性内存模型,并提供高带宽和无缝的多GPU系统。每个Grace Hopper超级芯片都拥有480GB的LPDDR5 CPU内存和96GB的快速HBM3,提供比PCIe Gen5多7倍的带宽,与NVLink-C2C互连。
NVLink开关系统使用第四代NVLink技术,将NVLink连接扩展到超级芯片,以创建一个两级、无阻塞、NVLink结构,可完全连接256个Grace Hopper超级芯片。这种结构提供900GBps的内存访问速度,托管Grace Hopper Superchips的计算底板使用定制线束连接到第一层NVLink结构,并由LinkX电缆扩展第二层NVLink结构的连接性。
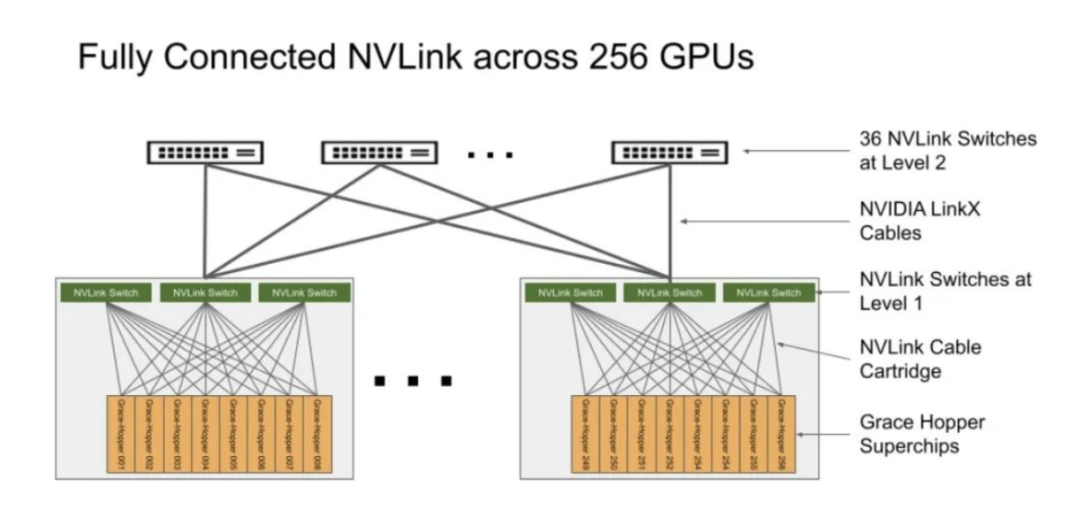
在DGX GH200系统中,GPU线程可以使用NVLink页表来访问来自其他Grace Hopper超级芯片的内存,并通过NVIDIA Magnum IO加速库来优化GPU通信以提高效率。该系统拥有128 TBps的对分带宽和230.4 TFLOPS的NVIDIA SHARP网内计算,可加速AI常用的集体运算,并将NVLink网络系统的实际带宽提高一倍。每个Grace Hopper Superchip都配备一个NVIDIA ConnectX-7网络适配器和一个NVIDIA BlueField-3 NIC,以扩展到超过256个GPU,可以互连多个DGX GH200系统,并利用BlueField-3 DPU的功能将任何企业计算环境转变为安全且加速的虚拟私有云。
对于受GPU内存大小瓶颈的AI和HPC应用程序,GPU内存的代际飞跃可以显著提高性能。对于许多主流AI和HPC工作负载,单个NVIDIA DGX H100的聚合GPU内存可以完全支持。对于其他工作负载,例如具有TB级嵌入式表的深度学习推荐模型(DLRM)、TB级图形神经网络训练模型或大型数据分析工作负载,使用DGX GH200可实现4至7倍的加速。这表明DGX GH200是更高级的AI和HPC模型的更好解决方案,这些模型需要海量内存来进行GPU共享内存编程。
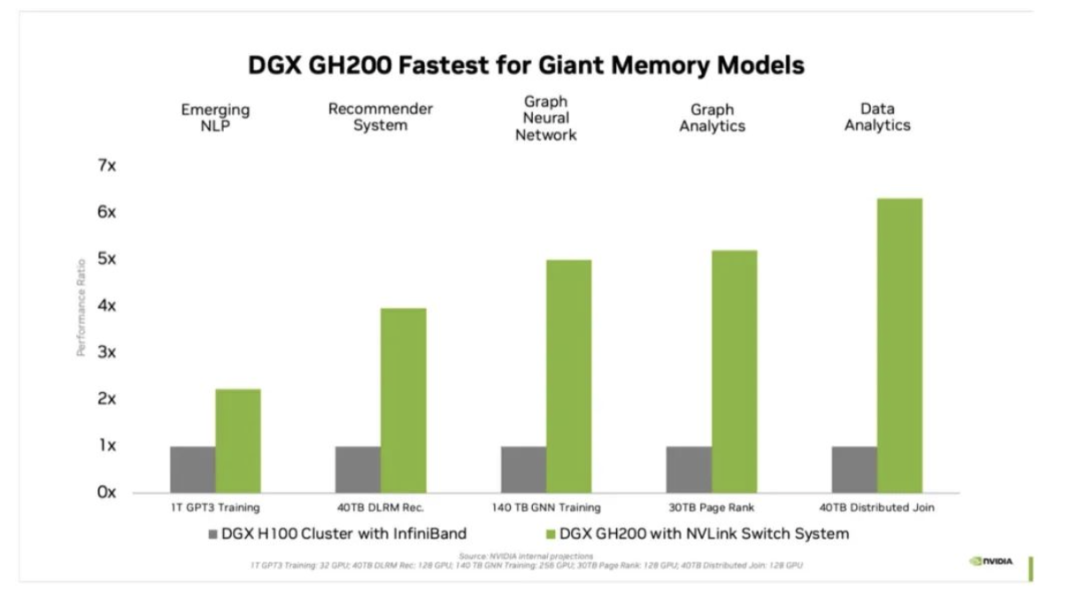
DGX GH200是专为最严苛的工作负载而设计的系统,每个组件都经过精心挑选,以最大限度地减少瓶颈,同时最大限度地提高关键工作负载的网络性能,并充分利用所有扩展硬件功能。这使得该系统具有高度的线性可扩展性和海量共享内存空间的高利用率。
为了充分利用这个先进的系统,NVIDIA还构建了一个极高速的存储结构,以峰值容量运行并处理各种数据类型(文本、表格数据、音频和视频),并且表现稳定且并行。
DGX GH200附带NVIDIA Base Command,其中包括针对AI工作负载优化的操作系统、集群管理器、加速计算的库、存储和网络基础设施,这些都针对DGX GH200系统架构进行了优化。此外,DGX GH200还包括NVIDIA AI Enterprise,提供一套经过优化的软件和框架,可简化AI开发和部署。这种全堆栈解决方案使客户能够专注于创新,而不必担心管理其IT基础架构。
审核编辑:汤梓红
-
NVIDIA
+关注
关注
14文章
5324浏览量
106645 -
AI
+关注
关注
88文章
35487浏览量
281320 -
英伟达
+关注
关注
22文章
3957浏览量
94088 -
超级芯片
+关注
关注
0文章
38浏览量
9112 -
生成式AI
+关注
关注
0文章
532浏览量
844
发布评论请先 登录
使用NVIDIA Earth-2生成式AI基础模型革新气候建模
Oracle 与 NVIDIA 合作助力企业加速代理式 AI 推理

NVIDIA Omniverse扩展至生成式物理AI领域
MediaTek与NVIDIA携手设计GB10 Grace Blackwell超级芯片
NVIDIA推出多个生成式AI模型和蓝图
联发科与NVIDIA合作 为NVIDIA 个人AI超级计算机设计NVIDIA GB10超级芯片
NVIDIA发布高性价比生成式AI超级计算机
NVIDIA 推出高性价比的生成式 AI 超级计算机

NVIDIA推出全新生成式AI模型Fugatto
赖耶科技通过NVIDIA AI Enterprise平台打造超级AI工厂
NVIDIA助力Amdocs打造生成式AI智能体
NVIDIA 以太网加速 xAI 构建的全球最大 AI 超级计算机






 工商网监
工商网监
评论