 介绍第一个结合相对和绝对深度的多模态单目深度估计网络
介绍第一个结合相对和绝对深度的多模态单目深度估计网络

背景
单目深度估计分为两个派系,metric depth estimation(度量深度估计,也称绝对深度估计)和relative depth estimation(相对深度估计)。
绝对深度估计:估计物体绝对物理单位的深度,即米。预测绝对深度的优点是在计算机视觉和机器人技术的许多下游应用中具有实用价值,如建图、规划、导航、物体识别、三维重建和图像编辑。然而,绝对深度股即泛化能力(室外、室内)极差。因此,目前的绝对深度估计模型通常在特定的数据集上过拟合,而不能很好地推广到其他数据集。
相对深度估计:估计每个像素与其它像素的相对深度差异,深度无尺度信息,可以各种类型环境中的估计深度。应用场景有限。
导读
现有的单目深度估计工作,要么关注于泛化性能而忽略尺度,即相对深度估计,要么关注于特定数据集上的最先进的结果,即度量深度(绝对深度)估计。论文提出了第一种结合这两种形态的方法,从而得到一个在泛化性能良好的同时,保持度量尺度的模型:ZoeD-M12-NK。
具体来说,论文框架包括两个关键组成部分:相对深度估计网络和绝对深度估计网络。相对深度估计网络学习提取相邻像素之间的深度差异信息,而绝对深度估计网络则直接预测绝对深度值。
使用这种框架,论文方法能够将已有数据集的深度信息转移到新的目标数据集上,从而实现零样本(Zero-shot)深度估计。在实验中,论文方法使用了几个标准数据集进行测试,并证明了所提方法在零样本深度估计方面比现有SOTA表现更好。
贡献
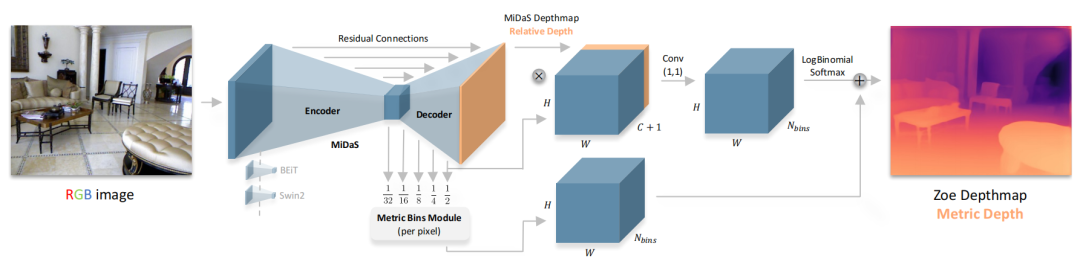
本文中,作者提出了一个两阶段的框架,使用一个通用的编码-解码器架构进行相对深度估计的预训练,在第二阶段添加绝对深度估计的轻量级head(metric bins module),并使用绝对深度数据集进行微调。本文的主要贡献是:
ZoeDepth 是第一个结合了相对深度和绝对深度的方法,在保持度量尺度的同时,实现了卓越的泛化性能。
ZoeDepth 的旗舰模型 ZoeD-M12-NK 在12个数据集上使用相对深度进行预训练,并在两个数据集上使用绝对深度进行微调,使其在现有SOTA上有了明显的提高
ZoeDepth 是第一个可以在多个数据集(NYU Depth v2 和 KITTI)上联合训练而性能不明显下降的模型,在室内和室外域的8个未见过的数据集上实现了前所未有的零样本泛化性能
ZoeDepth 弥补了相对深度估计和绝对深度估计之间的差距,并且可以通过在更多的数据集上定义更细化的域和,并在更多的绝对深度数据集微调来进一步改进网络性能。
方法
论文首先使用一个Encoder-Decoder的backbone进行相对深度预测,然后将提出的metric bins 模块附加在decoder上得到绝对深度预测头(head),通过添加一个或多个head(每个数据集一个)来进行绝对深度估计。最后再进行端到端的微调。下面介绍每个head(metric bins mdule)是怎么设计的:
LocalBins review
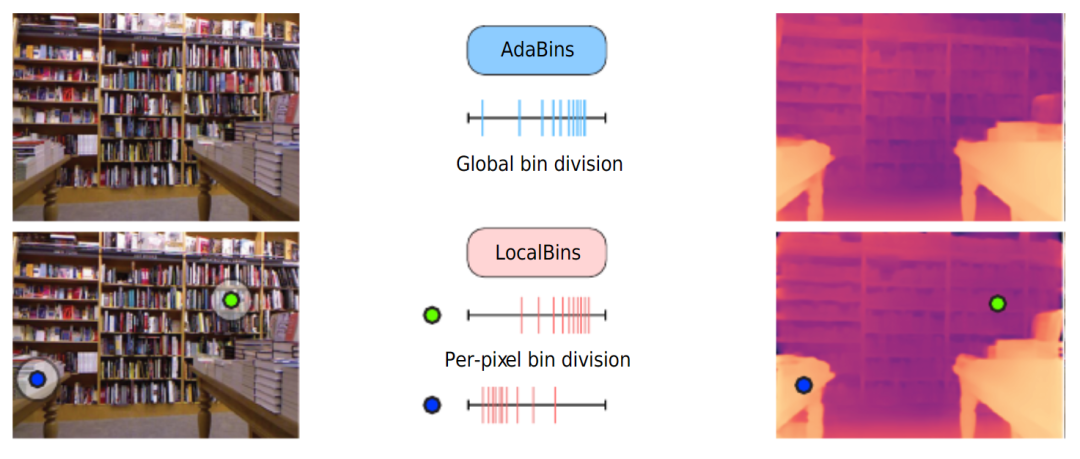
global adaptive bins vs local adaptive bins
不同RGB输入对应的深度分布会有很大的不同,目前的神经网络架构主要是在低分辨率的bottleneck获取全局信息,而不能很好地在高分辨率特征获取全局特征,深度分布的这种变化使得端到端的深度回归变得困难。因此,此前的一些方法提出将深度范围划分为一定数量的bin,将每个像素分配给每个bin,将深度回归任务转换为分类任务。
最终深度估计是bin中心值的线性组合。上图介绍了两种划分bin的方法,AdaBins预测了完整图像的分布,LocalBins预测了每个像素周围区域的分布。本文采用了类似于LocalBins的这种方式。
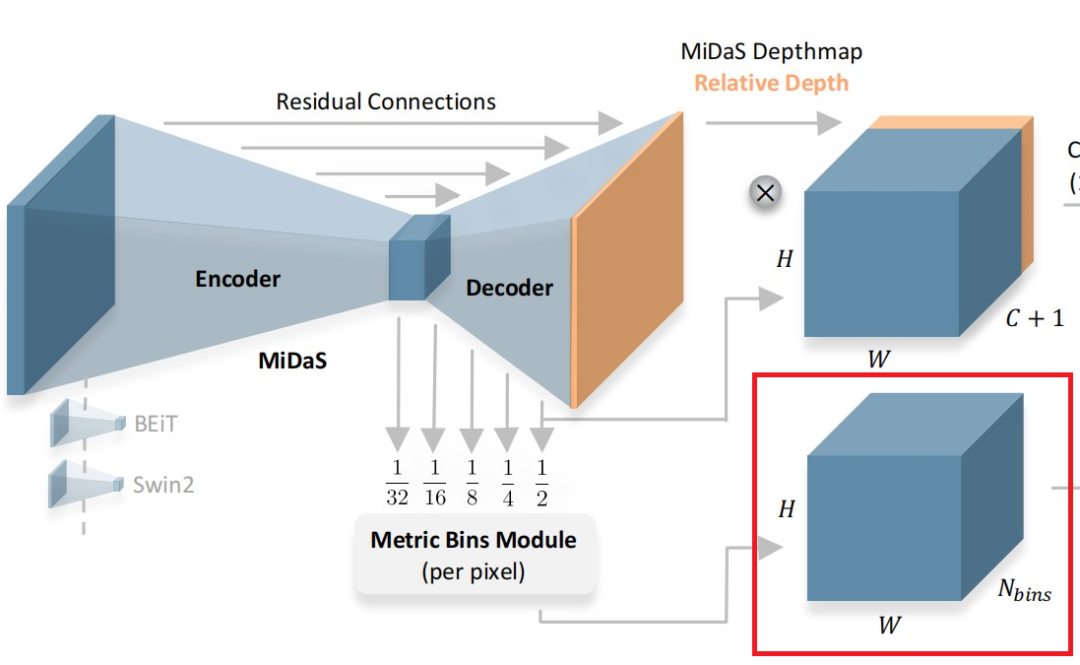
Metric bins
具体来说,LocalBins使用一个标准的encoder-decoder作为基本模型,并附加一个模块,该模块将encoder-decoder的多尺度特征作为输入,预测每个像素深度区间上的个bins中心值(channel)。一个像素的最终深度,由个bin经过softmax得到的概率加权其bin中心值的线性组合得到:
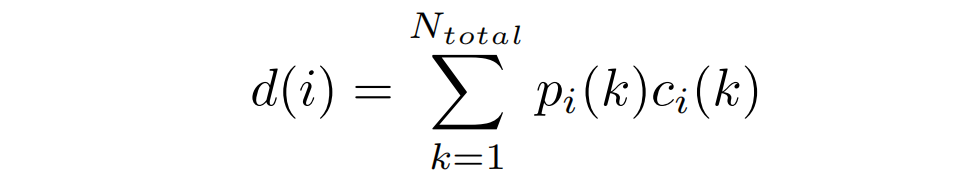
Metric bins module
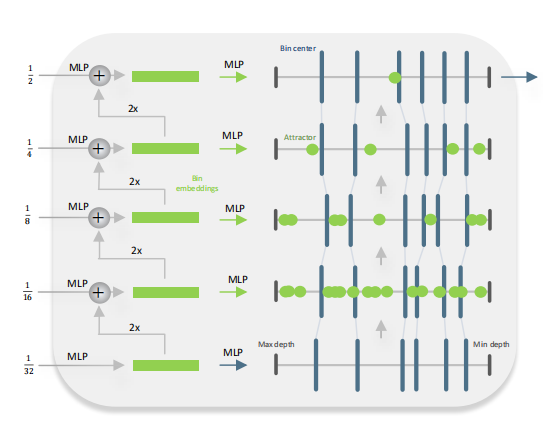
Metric Bins Module
如上图所示,Metric bins模块以MiDaS[1](一种有监督的Zero-shot深度估计方法)的解码器的多尺度(五层)特征作为输入,预测用于绝对深度估计的深度区间的bins的中心。注意论文在bottleneck层就直接预测每个像素上所有的bins(即channel的维度直接就是)。然后在decoder上使用attractor layers逐步进行细化bin区间。
Attract instead of split
论文通过调整bin,在深度区间上向左或向右移动它们,来实现对bin的多尺度细化。利用多尺度特征,论文预测了深度区间上的一组点用来”吸引“bin的中心。
具体地说,在第1个decoder层,MLP将一个像素处的特征作为输入,并预测该像素位置的吸引点。调整后的bin中心为,调整如下:
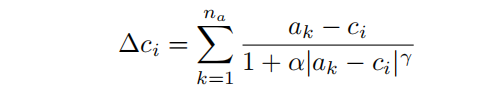
其中,超参数和决定了attractor(吸引子)的强度。论文把这个attractor命名为inverse attractor。此外,论文还实验了一个指数变量:
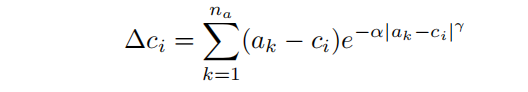
实验表明,inverse attractor可以导致更好的性能。论文中,深度区间设置了个bin,decoder设置了个attractor。
Log-binomial instead of softmax
为了得到最终的绝对深度预测,每个像素上深度区间内的每个bin通过softmax可以得到其概率,所有的bin的中心进行按照片概率线性组合得到该像素的深度值。
尽管softmax在无序类中运行得很好,但由于深度区间内bin本身是有序的,softmax方法可能导致附近的bin的概率大大不同,因此论文使用具有排序感知的概率预测:
论文使用一个二项式分来预测概率,将相对深度预测与解码器特征连接起来,并从解码器特征中预测一个2通道输出(q - mode和t - temperature),通过以下方法获得第k个bin中心的概率得分:
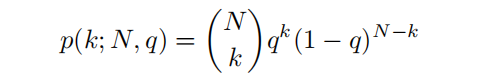
然后再通过:
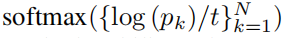
得到最终的概率值。
训练策略
Metric fine-tuning on multiple datasets
在具有各种场景的混合数据集上训练一个绝对深度模型是很困难的,论文首先预训练一个的相对深度估计的backbone,在一定程度上减轻了对多个数据集的微调问题。然后为模型配备多个Metric bins模块,每个场景类型(室内和室外)对应一个。最后再对完整的模型进行端到端微调。
Routing to metric heads
当模型有多个绝对深度头时,在推理的时候,算法需要根据输入数据的类型,通过一个“路由器”来选择用于特定输入的绝对深度头。
论文提供了三种“路由”策略:
Labeled Router(R.1):训练多个模型,给它们打上场景标签,推理时根据场景手动选择模型
Trained Router(R.2):训练一个MLP分类器,它根据bottleneck预测输入图像的场景类型,然后“路由”到相应的head,训练的时候需要提供场景类型的标签
Auto Router(R.3):跟第二种类似,但是训练和推理过程中不提供场景的标签。
实验
Comparison to SOTA on NYU Depth V2
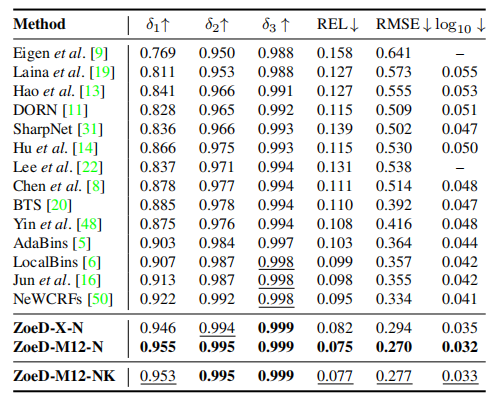
表1 Quantitative comparison on NYU-Depth v2
在没有任何相对深度预训练的情况下,论文的模型ZoeD-X-N预测的绝对深度可以比目前的SOTA NeWCRFs提高13.7% (REL = 0.082)。
通过对12个数据集进行相对深度预训练,然后对NYU Depth v2进行绝对深度微调,论文的模型ZoeD-M12-N可以在ZoeD-X-N上进一步提高8.5%,比SOTA NeWCRFs提高21%(REL = 0.075)。
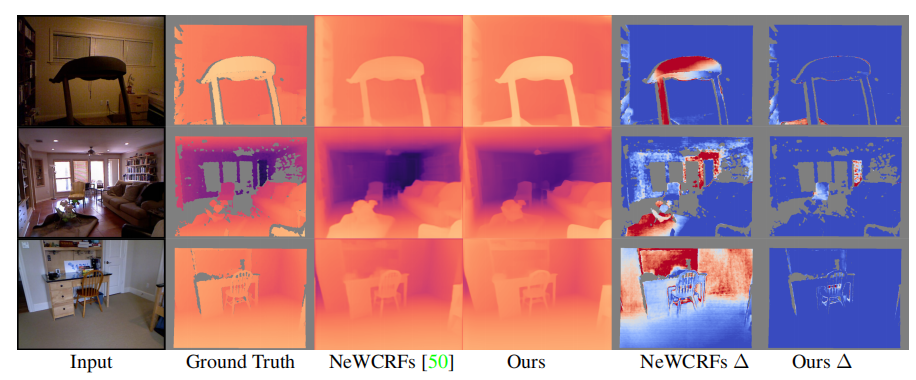
Qualitative comparison on NYU Depth v2
上面的可视化可以看出,论文方法始终以更少的误差,产生更好的深度预测(蓝色表示误差小)。
Universal Metric SIDE
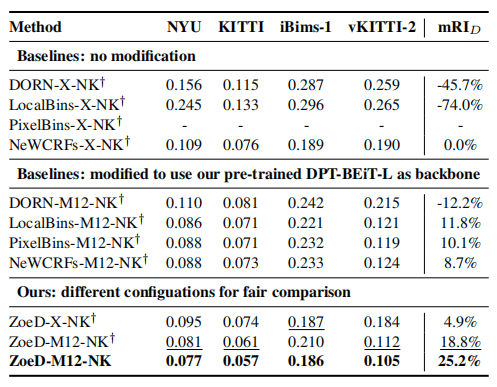
表2 Comparison with existing works when trained on NYU and KITTI
使用跨域数据集(室内NYU和室外KITTI(NK))进行绝对深度训练的模型通常表现更差,如上表2与表1的对比所示,论文将最近的一些方法在室内和室外数据集上进行联合训练,从结果可以看到,这些方法的性能都显著下降,甚至直接无法收敛。而本文的方法ZoeD-M12-NK**只下降了8%**(REL 0.075 to 0.081),显著优于SOTA NeWCRFs。
表2中,“”表示使用一个head,可以看到,使用多head的网络,泛化能力更强,这些结果表明,Metric Bins模块比现有的工作更好地利用了预训练,从而改进了跨域的自适应和泛化(Zero-shot性能)。
Zero-shot Generalization
论文将所提模型在8个未训练的室内和室外数据上进行Zero-shot测试,来评估所提方法的泛化能力。

Zero-shot transfer
Zero-shot transfer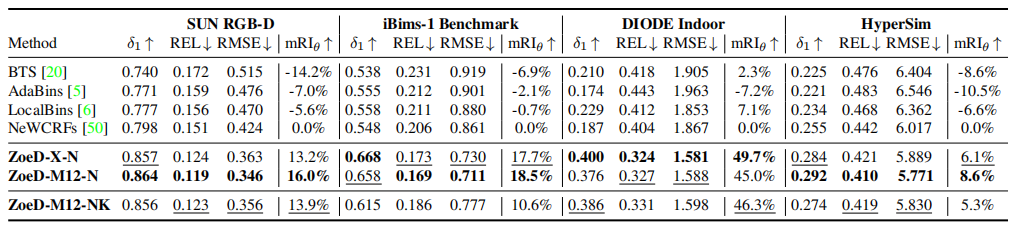
表3 Quantitative results for zero-shot transfer to four unseen indoor datasets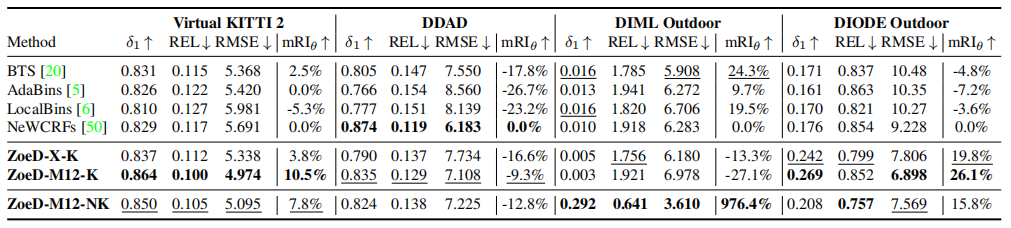
表4 Quantitative results for zero-shot transfer to four unseen outdoor datasets
如表3所示,在室内数据测试中,ZoeD-M12-N能够取得最好的效果(在12个相对深度数据集上预训练,只对NYU数据集进行微调),同时在室内NYU数据集和室外KITTI数据集进行微调效果次之,不使用12个相对深度数据集上预训练最差,但都显著高于SOTA。如表4和上图所示,在室外数据测试中,结论类似。甚至在达到了976.4%的提升!,这证明了它前所未有的Zero-shot能力。
消融实验
Backbones
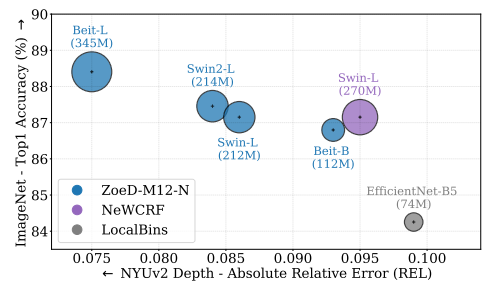
Backbone ablation study
在图像分类task中的backbone性能与深度估计性能之间有很强的相关性。较大的backbone可以实现较低的绝对相对误差(REL)。
Metric Bins Module
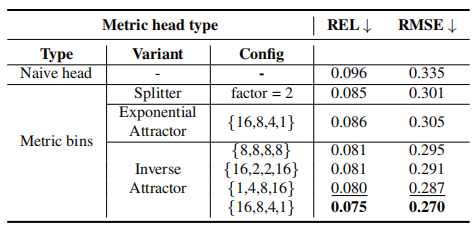
Metric head variants
不同的MLP中的分裂因子(Splitter)和吸引子(Attractor)的数量对结果有影响。
Routers
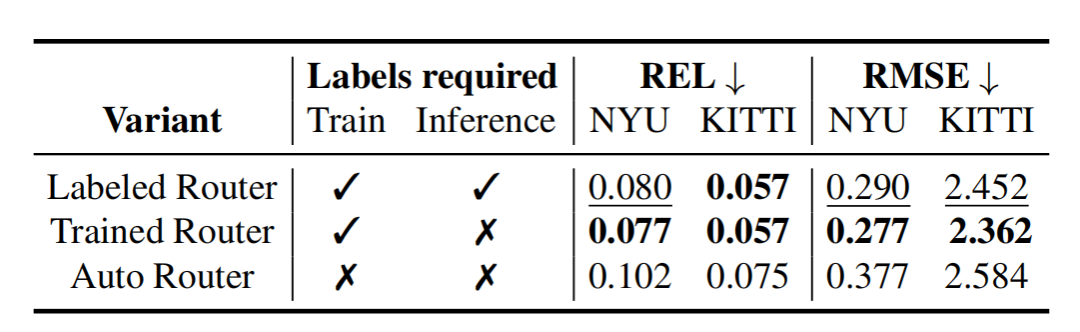
Router variants
Trained Router效果显著由于另外两种路由策略。
总结
论文提出了ZoeDepth,第一个结合了相对深度和绝对深度而性能没有显著下降的方法,弥补相对和绝对深度估计性能之间的差距,在保持度量尺度的同时,实现了卓越的泛化性能。ZoeDepth是一个两阶段的工作,在第一阶段,论文使用相对深度数据集对encoder-decoder架构进行预训练。在第二阶段,论文基于所提的Metric bins 模块得到domain-specific头,将其添加到解码器中,并在一个或多个数据集上对模型进行微调,用于绝对深度预测。
提出的架构显著地改进了NYU Depth v2的SOTA(高达21%),也显著提高了zero-transfer的技术水平。论文希望在室内和室外之外定义更细粒度的领域,并在更多的绝对深度数据集上进行微调,可以进一步改善论文的结果。在未来的工作中,论文希望研究ZoeDepth的移动架构版本,例如,设备上的照片编辑,并将该工作扩展到双目深度估计。
审核编辑:刘清
-
解码器
+关注
关注
9文章
1190浏览量
42080 -
机器人
+关注
关注
213文章
29829浏览量
213616 -
RGB
+关注
关注
4文章
808浏览量
60079 -
机器人技术
+关注
关注
18文章
194浏览量
32654
原文标题:Intel 开源新作 | ZoeDepth: 第一个结合相对和绝对深度的多模态单目深度估计网络
文章出处:【微信号:3D视觉工坊,微信公众号:3D视觉工坊】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
毫米之间定成败:PCB背钻深度设计与生产如何精准把控
研华科技携手创新奇智推出多模态大模型AI一体机

大模型推理显存和计算量估计方法研究
汽车多模态交互测试:智能交互的深度验证

存储示波器的存储深度对信号分析有什么影响?
摩尔线程与当虹科技达成深度合作

海康威视发布多模态大模型文搜存储系列产品







 工商网监
工商网监
评论