 Vitis HLS工具简介及设计流程
Vitis HLS工具简介及设计流程

Vitis HLS 是一种高层次综合工具,支持将 C、C++ 和 OpenCL 函数硬连线到器件逻辑互连结构和 RAM/DSP 块上。Vitis HLS 可在Vitis 应用加速开发流程中实现硬件内核,并使用 C/C++ 语言代码在 Vivado Design Suite 中为赛灵思器件设计开发 RTL IP。
Vitis 高层次综合用户指南(UG1399)包括Vitis HLS 入门、Vitis HLS 硬件设计方法论、Vitis HLS C 语言驱动程序参考资料、Vitis HLS 命令参考资料、Vitis HLS 库参考资料,以及Vitis HLS 移植指南。由于本指南较长,下文仅摘录部分内容。如果您希望查阅完整版,请至文末链接点击下载。
Vitis HLS 简介
在 Vitis 应用加速流程中,在可编程逻辑中实现和最优化 C/C++ 语言代码以及实现低时延和高吞吐量所需的大部分代码修改操作均可通过 Vitis HLS 工具来自动执行。在应用加速流程中,Vitis HLS 的基本作用是通过推断所需的编译指示来为函数实参生成正确的接口,并对代码内的循环和函数执行流水打拍。Vitis HLS 还支持自定义代码以实现不同接口标准或者实现特定最优化以达成设计目标。
Vitis HLS 设计流程如下所述:
查看报告以分析和最优化设计。
将 C 语言算法综合到 RTL 设计中。
使用 RTL 协同仿真来验证 RTL 实现。
将 RTL 实现封装到已编译的对象文件(.xo) 扩展中,或者导出到 RTL IP。
高层次综合基础
赛灵思 Vitis HLS 工具可将 C 语言或 C++ 语言函数综合到 RTL 代码中,用于在可编程逻辑内进行加速。Vitis HLS 与Vitis 核开发套件和应用加速设计流程紧密集成。
使用高层次综合(HLS) 设计方法论的优势包括但不限于:
编译、仿真和调试 C/C++ 语言算法。
查看报告以分析和最优化设计。
将 C 语言算法综合到 RTL 设计中。
使用 RTL 协同仿真来验证 RTL 实现。
将 RTL 实现封装到已编译的对象文件(.xo) 扩展中,或者导出到 RTL IP。
HLS 包含以下阶段:
1调度可根据下列条件判定每个时钟周期内发生的运算:
运算的依赖关系何时已得到满足或者变为可用。
时钟周期长度或时钟频率。
运算完成所需时间(由目标器件来定义)。
可用资源分配。
整合任意用户指定的最优化指令。
2绑定会分配硬件资源用于实现调度的每项运算,并将运算符(例如,加法、乘法和移位)映射到特定 RTL 实现。例如,mult 运算可在 RTL 内作为组合乘法器或流水打拍乘法器来实现。
3控制逻辑抽取可创建有限状态机(FSM),根据定义的调度按顺序执行 RTL 设计中的运算。
以调度和绑定为例,下图显示了此代码示例的调度和绑定阶段的示例:

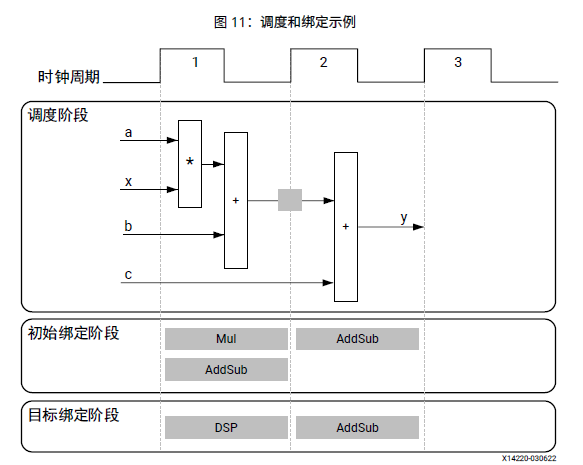
在此示例的调度阶段,根据高层次综合的调度,在每个时钟周期内将执行以下操作:
第一个时钟周期:乘法和第一次加法
第二个时钟周期:如果在第二个时钟周期内第一次加法的结果可用,则执行第二次加法并输出生成。
在最终的硬件实现中,高层次综合将顶层函数的实参实现为输入和输出 (I/O) 端口。在此示例中,实参是简单数据端口。因为每个输入变量都是 char 类型,所以输入数据端口位宽均为 8 位。return 函数为 32 位 int 数据类型,而输出数据端口位宽为 32 位。
在此示例的初始绑定阶段,高层次综合使用组合乘法器(Mul)实现乘法运算,并使用组合加法器/减法器(AddSub)实现两次加法运算。
在目标绑定阶段,高层次综合使用 DSP 模块资源实现乘法器和其中一项加法运算。部分应用使用大量二进制乘法器和累加器,这些乘法器和累加器最好在专用 DSP 资源内实现。DSP 模块是 FPGA 架构中可用的计算块,可在高性能和高效实现之间达成理想的平衡。
Vitis HLS 进程概述
Vitis HLS 基于工程,可包含多个变体(称为“解决方案”)以驱动综合与仿真。每个解决方案均可将 Vivado IP 流程或Vitis 内核流程设定为目标。基于目标流程,每个解决方案都将指定不同的约束和最优化指令,如 启用 Vivado IP 流程和启用 Vitis 内核流程中所述。
以下提供了典型设计流程中的综合、分析与最优化步骤:
1创建新的 Vitis HLS 工程。
2利用 C 语言仿真来验证源代码。
3运行高层次综合以生成 RTL 文件。
4分析结果,包括检验时延、启动时间间隔 (II)、吞吐量和资源使用情况。
5执行最优化,并按需重复此步骤。
6使用 C/RTL 协同仿真验证结果。
Vitis HLS 基于目标流程、默认工具配置、设计约束和您指定的任意最优化编译指示或指令来实现解决方案。您可使用最优化指令来修改和控制内部逻辑和 I/O 端口的实现,以覆盖工具的默认行为。
C/C++ 代码综合方式如下:
1顶层函数实参由 Vitis HLS 自动综合到 RTL I/O 端口接口内。如 定义接口 中所述,该工具创建的默认接口取决于目标流程、函数实参的数据类型和方向、默认接口模式以及用户指定的任何 INTERFACE 编译指示或指令(用于手动定义接口)。
2顶层 C/C++ 函数的子函数综合到 RTL 设计的层级内的各块中。
最终 RTL 设计包含与原始顶层 C 语言函数层级相对应的模块或实体层级。
Vitis HLS 会将子函数根据需要自动内联到更高层次的函数中或者内联到顶层函数中,以提升性能。
您可通过在解决方案中向子函数指定 INLINE 编译指示,或者使用 set_directive_inline 并将其设置为OFF 来禁用自动内联。
默认情况下,C 语言子函数的每次调用使用的 RTL 模块的实例是相同的。但您可以通过在解决方案中指定ALLOCATION 编译指示或者使用 set_directive_allocation 来实现多个 RTL 模块实例以提升性能。
3控制逻辑抽取可创建有限状态机(FSM),根据定义的调度按顺序执行 RTL 设计中的运算。
Vitis HLS 工具将不会展开循环,除非这样能够提升解决方案性能,如展开嵌套的循环以对顶层函数进行流水打拍。收起循环时,综合会为循环的单次迭代创建逻辑,RTL 设计会为序列中循环的每次迭代都执行此逻辑。展开循环允许循环的部分或全部迭代并行发生,但也会耗用更多器件资源。
您可以使用 UNROLL 编译指示或 set_directive_unroll 命令来手动展开循环。
循环还可通过如下任一方法进行流水打拍:通过有限状态机高精度实现(循环流水打拍)或者采用基于较低精度的握手的实现(数据流)。
4代码中的阵列将综合到最终 FPGA 设计中的块 RAM (BRAM)、LUT RAM 或 UltraRAM 中。
如果阵列位于顶层函数接口上,那么高层次综合可将此阵列作为端口来实现,以便访问设计外部的块 RAM。
您可使用 ARRAY_PARTITION 或 ARRAY_RESHAPE 编译指示或者关联的 set_directive_array 命令更改。
综合后,您可以对先前生成的各项报告中的结果进行分析,以确定结果质量。分析结果后,您可以为工程创建其它解决方案,指定不同的约束和最优化指令,并对这些结果进行综合与分析。您可对不同解决方案的结果进行比较,查看哪些有效,哪些无效。您可重复此过程,直至设计达成所期望的性能特性为止。您可使用多种解决方案持续进行开发,同时仍可保留先前的解决方案。
原文标题:Vitis 高层次综合用户指南
文章出处:【微信公众号:Xilinx赛灵思官微】欢迎添加关注!文章转载请注明出处。
-
赛灵思
+关注
关注
33文章
1797浏览量
132459 -
C语言
+关注
关注
180文章
7633浏览量
142127 -
Vitis
+关注
关注
0文章
150浏览量
7979
原文标题:Vitis 高层次综合用户指南
文章出处:【微信号:赛灵思,微信公众号:Xilinx赛灵思官微】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何使用AMD Vitis HLS创建HLS IP

使用AMD Vitis Unified IDE创建HLS组件
如何在Unified IDE中创建视觉库HLS组件

FPGA高层次综合HLS之Vitis HLS知识库简析
使用Vitis HLS创建属于自己的IP相关资料分享
Vivado HLS和Vitis HLS 两者之间有什么区别
基于Vitis HLS的加速图像处理
Vitis HLS如何添加HLS导出的.xo文件
Vitis HLS前端现已全面开源
Vitis HLS知识库总结
理解Vitis HLS默认行为
HLS最全知识库
AMD全新Vitis HLS资源现已推出
如何在Vitis HLS GUI中使用库函数?






 工商网监
工商网监
评论