 如何使用多个DPU实现云级架构
如何使用多个DPU实现云级架构

区别SmartNIC 与数据处理器(DPU) 的依据是它的功能,而不是形态。对称为 SmartNICs 的一类数据中心智能网卡来说,它需要支持硬件传输和用于虚拟交换机加速的可编程数据路径。这些功能是必要的,但不足以使 其 成为 DPU 。一个真正的 DPU 还必须包括一个易于扩展的、 C语言编程的 Linux 环境,使数据中心架构师能够虚拟化云中的所有资源,并使它们看起来像本地资源。为了更好地理解为什么需要这样,让我们讨论一下?创建 DPU 的原因。
为什么世界需要 DPU
世界需要 DPU 的一个最重要原因是,目前的应用程序和数据中心的设计让 CPU 内核花费了太多的开销来支持网络功能。随着网络速度的提高(现在每条链路的速度高达 200gb / s ), CPU 使用了太多宝贵的内核来进行网络流量的分类、跟踪和控制。这些昂贵的 CPU 内核是为通用应用程序处理而设计的,最不值得的就是将它们用于网络数据包的查找和管理。毕竟,用CPU内核来分析数据并得到结果才是它们真正的价值所在。
计算虚拟化的引入使这种情况变得更糟,因为无论是在同一台服务器上运行的VM 或容器之间, 还是和其他的计算服务器或存储服务器之间,都需要更多的流量。软件定义存储( SDS )、超聚合基础设施( HCI )和大数据等的应用程序会增加服务器之间的东西向的通信流量,另外, RDMA 也通常被用来加速服务器之间的数据传输,这使得服务器对网络基础功能的处理要求更高。
随着通信量的增加和 VXLAN 、 NVGRE 或 GENEVE 等覆盖网络的使用,公共云和私有云越来越流行。但其需求的多层封装也进一步增加了网络的复杂性。软件定义的网络( SDN )带来了额外的数据包控制和处理的需求,这让 CPU 花费珍贵的内核来处理openvswitch ( OVS )等更多工作。
DPU 可以比标准 CPU 更快、更高效、更低的成本处理所有这些虚拟化的功能( SR-IOV 、 RDMA 、覆盖网络流量封装、 OVS 卸载)。
不可忽视的安全隔离
有时,出于安全原因,您需要将网络与 CPU 隔离开来。网络是黑客攻击或恶意软件入侵最有可能的载体,但也是你第一个发现或阻止黑客攻击的地方。它同时也是最有可能实现在线加密的地方。
DPU 作为特殊的 网卡 ,是检查网络流量、阻止攻击和加密传输的首选,最简单有效,既有性能优势,又有安全优势,因为它消除了将所有传入和传出的数据让CPU处理 并通过 PCIe 总线的频繁需要。它通过与主机CPU 分开运行来提供安全隔离。如果主机CPU 受损, DPU 仍然可以检测或阻止恶意活动。 DPU 可以在不立即涉及 CPU 的情况下检测或阻止攻击。
虚拟化存储和云
DPU 的一个较新用例是虚拟化软件定义的存储、超聚合基础设施和其他云资源。在虚拟化需求爆发之前,大多数服务器只运行本地存储,这并不总是高效的,但却很简单易行。每个操作系统、应用程序和 hypervisor 都知道如何使用本地存储。
然后是网络存储的兴起: SAN 、 NAS ,以及最近出现的 NVMe of Fabrics(NVMe-oF)。但是,并不是每个应用程序都是原生的并可感知 SAN。另外,一些操作系统和 hypervisor ,比如 Windows 和 VMware ,都还没有考虑到 NVMe-oF 。 DPU 可以支持虚拟化网络存储,即可以更高效也更易于管理,让虚拟化网络存储看起来就像本地存储,非常易于应用程序使用。一个 DPU 甚至可以虚拟化 GPU或其他神经网络处理器,这样任何服务器在需要时都可以通过网络访问任意数量的 GPU。
类似的DPU优势也适用于软件定义的存储和超聚合基础架构。两种架构传统上都使用管理层软件(通常作为 VM 或 hypervisor的一部分来运行)来虚拟化和抽象本地存储和网络,以使其可供集群中的其他服务器或客户端使用。这对于服务器的快速部署,及共享存储资源带来了极大的便利。然而,管理层和虚拟化占用了许多本应运行应用程序的 CPU 资源。更糟糕的是,网络带宽越大,存储速度越快,需要损耗的CPU 的资源就越多。
这也是智能 DPU 创造效率的地方。首先,它卸载并帮助虚拟化网络。它们加速了私有云和公共云,这就是为什么它们有时被称为 CloudNICs 。它们可以卸载网络和大部分甚至全部的存储虚拟化。 DPU 还可以减轻 SDS 和 HCI 的各种功能,如压缩、加密、重复数据消除、 RAID 、报告等。这一切都是为了把更昂贵的 CPU 内核送回它们最擅长的领域:运行应用程序。

图 1 。 DPU 是一种可编程的、专用的电子电路板,具有数据中心计算数据处理的硬件加速功能
必须有硬件加速
在介绍了主要的 DPU 用例之后,您应该已经清楚何时何地使用DPU会带来最大的好处:加速和卸载网络流量,虚拟化存储资源,通过网络共享 GPU, 以及支持 RDMA 和执行加解密。
那么 最优的DPU 需要具备什么?必须有硬件加速。 硬件加速提供了最好的性能和效率,这也意味着用更少的开销进行更多的卸载。为某些功能提供专用硬件的能力让采用DPU 的机会大大增加。
必须可编程
为了获得最佳性能,大多数加速功能必须在硬件上运行。为了获得最大的灵活性,这些功能的控制和编程必须在软件中运行。
在 DPU 上有许多功能可以编程,通常,特定的卸载方法、加密算法和传输机制不会有太大变化,但是路由规则、流表、加密的密钥和网络地址会一直会变化。前者是数据平面,后者是控制平面。数据平面规则和算法经过标准化后,可以被固化到芯片中。但控制平面规则和要求变化太快,无法固化,但可以在 FPGA 上运行(偶尔修改,但很困难),也可以在 支持C语言编程的 Linux 环境中运行(容易且可以经常修改)。
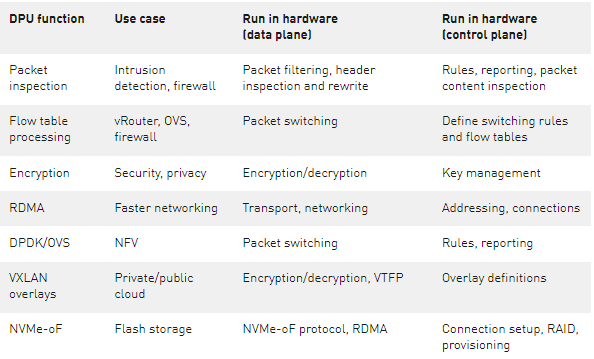
表 1 。 DPU 功能指南
在 DPU 上需要多少编程?
您可以选择在DPU 上有多少功能要由运行程序完成,也就是说,处理数据包的数据平面由DPU处理 (硬件加速或/和 开发的程序),同时, 用于设置和管理规则的控制平面,可以由用户决定是由DPU来全权处理,还是由位于其他地方的处理器,如 CPU来处理 。
例如,使用 Open vSwitch ,包交换可以在软件或硬件中完成,而控制平面则可以在 CPU 或 DPU 上运行。如果是常规的基础网卡,所有的交换和控制都必须由 CPU 上的软件完成。 使用 SmartNIC 时,交换在网卡的 ASIC 上运行,但控制仍必须在 CPU 上完成。 只有在真正的 DPU 中,交换是由DPU卡上的 ASIC完成,而控制平面也是在DPU包含的 Arm 内核上运行。
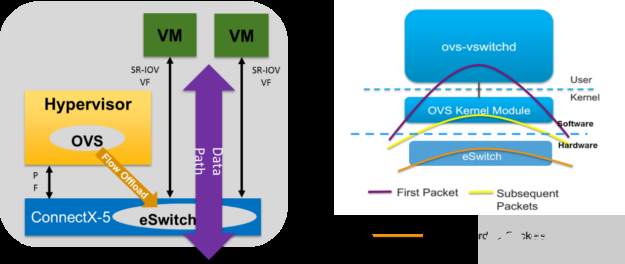
图 2 。 ConnectX-5 SmartNIC 卸载 OVS 切换到 NIC 硬件
DPU 和 SmartNIC 哪一个最好?
为了在数据中心充分实现应用程序的效率,传输卸载、可编程的数据平面以及用于虚拟交换的硬件卸载都是至关重要的功能。根据定义,支持这些功能是 SmartNIC 的重要部分,。但只是 DPU 的最基本要求之一, 并不能将 SmartNIC 提升到 DPU 的级别。
客户经常告诉我们,他们必须有 DPU,因为他们需要可编程的虚拟交换硬件加速支持。这主要是某些供应商的误导。如果某个供应商只能提供昂贵的、几乎无法编程的产品,他会告诉客户,“ DPU ”是实现这一目标的唯一方法。对我们来说,这种情况只需要我们的 ConnectX 系列的 SmartNIC 。
我觉得要将 SmartNIC 提升到 DPU 的高度,还需要支持更多的功能,比如能够运行控制平面,以及在 Linux 环境下提供 C 语言编程。我们很自豪地提供 BlueField DPU 来支持所有这些,它包括 ConnectX 的所有智能 网卡 功能,以及 4 到 16 个 64 位的 Arm 内核,当然,所有这些内核都运行 Linux ,并且易于编程。
在计划下一个基础架构的构建或更新时,请记住以下要点:
DPU 在卸载网络功能和虚拟化存储、网络和 GPU 等资源方面越来越有用
SmartNIC 可以在硬件中加速数据平面任务,但必须依靠host CPU来运行控制平面
控制平面软件和其他管理软件可以在常规 CPU 或 DPU 上运行。
NVIDIA 提供业界最佳的SmartNICs ( ConnectX )、 FPGA NIC ( Innova )和完全可编程并支持数据平面及控制平面 DPU s ( BlueField 可编程 DPU )。
关于作者
Kevin Deierling 从 2013 年 3 月开始担任 Mellanox 的营销副总裁。此前,他曾担任 Genia Technologies 的技术副总裁、 Silver Spring Networks 的首席架构师,并在 Spans Logic 负责营销和业务开发
审核编辑:郭婷
-
cpu
+关注
关注
68文章
11118浏览量
218324 -
Linux
+关注
关注
88文章
11536浏览量
214911 -
数据中心
+关注
关注
16文章
5292浏览量
73730
发布评论请先 登录
铁路巡检升级:云翎智能高精度执法记录仪+指挥调度系统实现故障秒级响应

MESH自组网赋能森林防火:云翎智能无线自组网厘米级定位与实时火情传输

DPU核心技术论文再次登陆体系结构领域旗舰期刊《IEEE Transactions on Computers》
第三届NVIDIA DPU黑客松开启报名
多模融合,秒级响应-云翎智能应急指挥箱打造全域指挥“移动中枢”

EM储能网关 ZWS智慧储能云应用(11) — 一级架构 主从架构

Arm助力开发者加速迁移至Arm架构云平台 Arm云迁移资源分享
揭秘云计算架构的分层奥秘
HPC云计算的技术架构
FE1.1S的国产替代芯片DPU1.1S 高性能、低功耗4口高速USB2.0HUB控制器芯片 USB拓展坞等应用之选
利用NVIDIA DPF引领DPU加速云计算的未来
中科驭数凭借在DPU芯片领域的积累被认定为北京市知识产权优势单位






 工商网监
工商网监
评论