 口语语言理解在任务型对话系统中的探讨
口语语言理解在任务型对话系统中的探讨

1.1 研究背景与任务定义
口语语言理解在任务型对话系统中扮演了一个非常重要的角色,其目的是识别出用户的输入文本中蕴含的意图和提及到的槽位,一般被分为意图识别和槽位填充两个子任务[1]。以句子“use netflix to play music”为例,意图识别将整个句子的意图分类为播放音乐(PlayMusic),槽位填充为句子中的每个单词赋予不同的槽位标签(即,O, B-service,O,O,O)。从任务类型来区分,意图识别属于句子分类任务,槽位填充可以被建模成序列标注任务。 与英文口语语言理解相比,中文口语语言理解面临了一个独特的挑战:在完成任务之前需要进行词语切分。尽管事先做了分词,不完美的分词系统仍然会错误识别槽位的边界,随即预测了错误的槽位类别,使得模型的性能遭受来自分词系统的错误级联。

图1 中文口语语言理解示例
1.2 研究动机
为了避免来自分词系统的错误级联,Liu等人[2]提出了一个基于字符的联合模型完成中文口语语言理解,达到了当时最好的效果。
然而,直观上,中文词语信息的引入有助于对中文文本的理解,进而正确完成意图识别和槽位填充任务。
以图1为例,正确的中文分词为"周冬雨 / 有 / 哪些 / 电影"。如果不引入这种分词信息作为补充,可能会给"周"赋予Datetime_date槽位标记,将"冬雨"看作Datetime_time。而有了类似于"周冬雨"这样词语的帮助,检测正确的槽位标签Artist会变得异常容易。
除此之外,由于口语语言理解由两个类型不同又相互关联的任务组成,利用任务间的交互可以对在两个任务间建模细粒度的词语信息迁移起到重要的帮助。
所以,在考虑任务特性的同时引入词语信息是很有必要的。
因此,接下来的问题是:是否可以在避免分词系统错误级联、考虑口语语言理解任务特性的同时,引入中文词语信息增强中文意图识别和槽位填充。
为了解决此问题,我们提出了简单而有效的Multi-LevelWordAdapter (MLWA)模型引入中文词语信息,对意图识别和槽位填充进行联合建模。其中,1) sentence-level word adapter 直接融合词级别和字级别的句子表示实现对意图的识别;2) character-level word adapter 针对输入文本中的每个字动态地确定不同字特征和不同词特征之间的融合比例,进而得出该字的槽位标签,以达到对词语知识的细粒度组合这一目的。另外,word adapter可以作为一个依附于输出层的插件被应用于各种基于字符的中文口语语言理解模型,其无需改变原始模型其他分量的特性带来了更多的应用灵活性。
2. 模型
2.1 整体框架
模型以一个普通的基于字符的模型(图2 (a))为基础,附以multi-level word adapter模块(图2 (b))针对意图识别和槽位填充分别引入并捕获句子级和字符级词语信息。
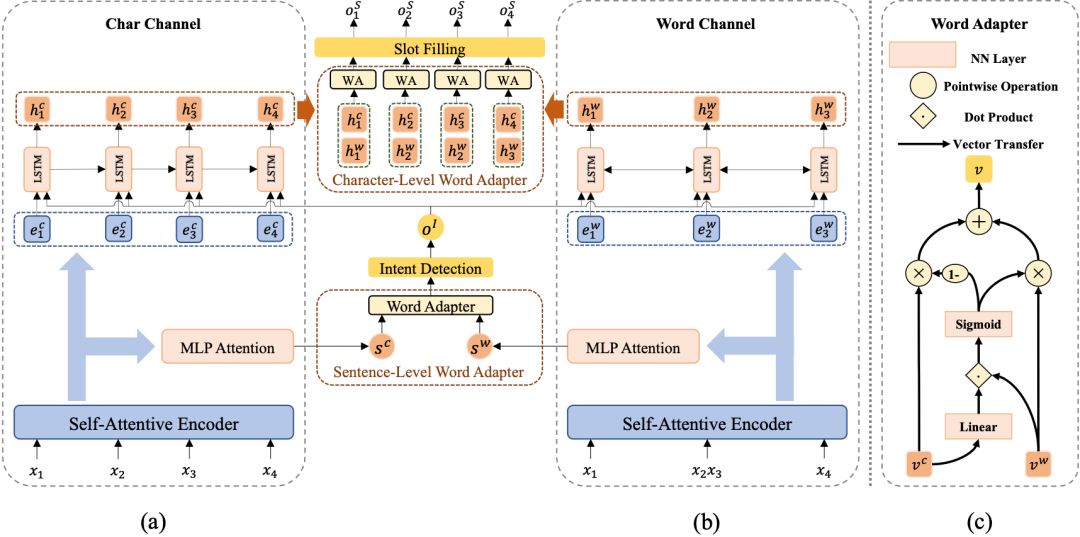
图2 Multi-Level Word Adapter 整体框架
2.2 Vanilla Character-based Model
Char-Channel Encoder
自注意力编码器(Self-Attentive Encoder)[3]由抽取序列上下文信息的自注意力模块[4]和捕获序列信息的双向LSTM[5]组成。其接收中文字输入序列 = ,获得BiLSTM和self-attention的输出后,连接两者输出字符编码表示序列 = 。
Intent Detection and Slot Filling
意图识别和槽位填充均以自注意力编码器的输出为基础,进行进一步的编码,即两者共享底层表示信息。其中,意图识别模块利用一个MLP Attention模块获得整个字序列的综合表示向量 ,进而完成对意图的分类(意图标签集表示为 ):
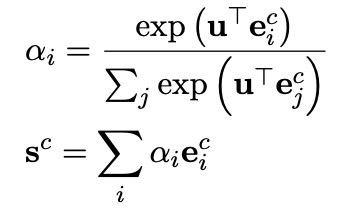
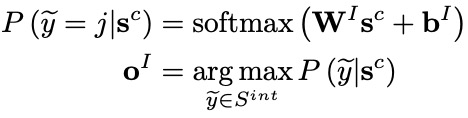
槽位填充应用一个单向LSTM作为解码器,在每个解码时间步 ,其接收每个字表示 ,意图标签编码 ,来自上一个时间步解码的槽位标签编码 ,输出解码器隐层向量 ,进而计算得到第 个字 的槽位标签(槽位标签集表示为 ):
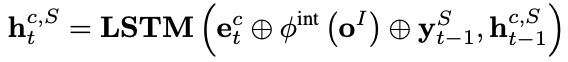
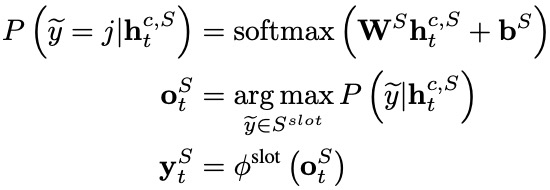
2.3 Multi-Level Word Adapter
Word-Channel Encoder
在我们的框架中,单词通道编码器独立于字符通道编码器,也就是说,如何编码单词信息,编码何种单词信息都是自由的,在这里以使用外部中文分词系统(CWS)为例。对字序列 进行分词可以得到单词序列 = 。与字符通道编码器相同,单词通道编码器利用另一个自注意力编码器生成单词编码表示序列 = 。
Word Adapter
word adapter 是一个简单的神经网络,可以适应性地融合不同的字特征的词语特征,图2 (c)显示了其内部结构。给定输入字符向量 和词语向量 ,word adapter可以计算两者之间的权重比例,进而加权求和得到融合后的特征向量:
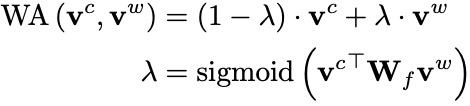
Sentence-Level Word Adapter
给定字符序列和单词序列的上下文表示序列 和 ,可以通过上文的MLP Attention模块获得两种序列的综合表示向量 和 。
随后,sentence-level word adapter计算融合后的综合向量 ,并利用它预测意图标签 :
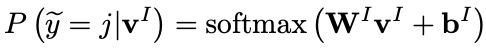
Character-Level Word Adapter
在完成槽位填充之前,我们首先采纳一个双向LSTM增强单词序列的表示。在每个时间步 ,单词通道的槽位填充编码器输出的隐层向量由相应的单词表示 和意图标签的编码 计算得到。
然后,character-level word adapter针对每个输入字符,为字符特征和词语特征的不同组合确定不同的融合比例:
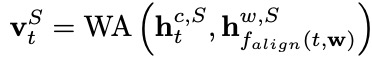
最后,我们利用融合后的表示 完成第 个字符的槽位标注:
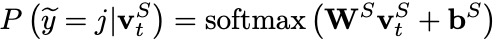
2.4 Joint Training
我们采纳联合训练策略优化模型,最终的联合目标函数如下, and 分别是正确的意图和槽位标签:
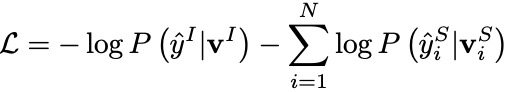
3. 实验
3.1 实验设置
数据集
我们在两个公开的中文数据集CAIS和ECDT-NLU上进行了实验,我们保持了两个数据集原分割不变。
CAIS中, 训练集包含7995个句子,验证集和测试集分别有994和1024个句子。
ECDT-NLU由2576个训练样本和1033个测试样本组成。
评价指标
与前人相同,我们使用以下三个指标来评价中文口语语言理解模型的性能:
F1值作为槽位填充任务的评价指标。
准确率(accuracy)作为意图识别任务的评价指标。
使用整体准确率(overall accuracy)指标评价句子级语义帧解析能力。一个整体准确的预测表示预测的意图和槽位标签与人工标注完全相同。
3.2 主实验结果
表1 主实验结果

所有的baseline模型均考虑了意图识别和槽位填充两个任务之间的相关性,并联合建模这两个相关任务。从结果可以看出:
我们的实验结果在所有指标上均超过了这些baseline模型,达到了当前最好的性能,证明了我们提出的multi-level word adapter的有效性。
Slot和Intent指标的提升表明利用multi-level word adapter融入单词信息可以促进模型对于中文意图和槽位的识别和标注。
整体准确率的提升归因于考虑了两个任务之间的相关性,并通过联合训练相互增强两者。
3.3 消融实验结果
为了验证已提出的word adapters的有效性,我们对以下几个重要分量执行了消融实验:
w/o Multiple Levels 设置中,我们移除了character-level word adapter,在对每个字符的槽位标记时使用相同的单词信息。
w/o Sentence-Level word adapter 设置中,不使用sentence-level word adapter,只使用字序列编码信息去完成意图识别。
w/o Character-Level word adapter 设置中,不使用character-level word adapter,只使用字序列编码信息去完成槽位填充。
表2 消融实验结果

上表是消融实验的结果,从中可以看出:
使用多层次机制带来了显著的正向效果,这从侧面证实了对于字符级的槽位填充任务,每个字需要不同的单词信息,即细粒度的词信息。
不使用sentence-level word adapter时,在ECDT-NLU数据集上,意图识别准确率出现了明显的下降,表明sentence-level word adapter可以抽取有利的词信息去提升中文意图识别。
不使用character-level word adapter时,两个数据集上的槽位填充指标出现了不同程度的下降,证明了词语信息可以为中文槽位填充的完成提供有效的指导信息(例如,明确的单词信息可以帮助模型检测单词边界)。
3.4 预训练模型探索实验
我们进一步在这两个数据集上探索了预训练模型的效果。我们将char-channel encoder替换为预训练模型BERT,模型的其他部分保持不变,进行fine-tuning训练,来观察我们提出的multi-level word adapter的效果。
表3 BERT模型探索结果

表3是对于BERT预训练模型的探索结果。其中,
Joint BERT 利用预训练模型BERT得到输入字序列的编码,经过线性分类层完成意图识别和槽位填充,随后应用多任务学习方法进行训练。
Our Model + BERT 是使用BERT替换掉char-channel encoder作为字序列的Encoder。具体来说,BERT的[CLS]输出向量作为字序列的综合向量,其他输出向量作为各字的表示向量。
实验结果表明,multi-level word adapter和BERT的结合可以进一步提升模型效果,证明了我们的贡献与预训练模型是互补的。
4.结论
在这篇文章中,我们的贡献如下:
我们首次利用一个简单有效的方法向中文口语语言理解中引入中文单词信息。
我们提出了一个多层次的单词适配器,句子级和字符级单词适配器分别向意图识别和槽位填充提供两个层次的单词信息表示,从而实现了不同级别任务的词信息表示定制化。
在两个公开数据集上进行的实验表明,我们的模型取得了显著性的改进,并实现了最佳的性能。此外,我们的方法与预训练模型(BERT)在性能上是互补的。
原文标题:【工大SCIR】首次探索中文词信息增强中文口语语言理解!
文章出处:【微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
责任编辑:haq
-
模型
+关注
关注
1文章
3533浏览量
50600 -
nlp
+关注
关注
1文章
490浏览量
22662
原文标题:【工大SCIR】首次探索中文词信息增强中文口语语言理解!
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
CPU密集型任务开发指导
基于MindSpeed MM玩转Qwen2.5VL多模态理解模型

千万级损失预警:你的DeepSeek部署正踩中这个隐形雷区
【「具身智能机器人系统」阅读体验】1.初步理解具身智能
深入理解C语言:循环语句的应用与优化技巧

循环神经网络在自然语言处理中的应用
使用LSTM神经网络处理自然语言处理任务
使用LLM进行自然语言处理的优缺点
AI对话魔法 Prompt Engineering 探索指南






 工商网监
工商网监
评论