 OpenAI推出两套多模态人工智能系统模型
OpenAI推出两套多模态人工智能系统模型

据外媒,知名机器学习公司OpenAI近日推出两套多模态人工智能系统模型DALL-E和CLIP,DALL-E可以基于文本直接生成图像,CLIP能够完成图像与文本类别的匹配。DALL-E可以将以自然语言形式表达的大量概念转换为恰当的图像,并使用了GPT-3 同样的方法,只不过DALL-E将其应用于文本-图像对。
另一个神经网络CLIP能够执行一系列视觉识别任务。给出一组以语言形式表述的类别,CLIP能够立即将一张图像与其中某个类别进行匹配,而且它不像标准神经网络那样需要针对这些类别的特定数据进行微调。在ImageNet基准上,CLIP的性能超过ResNet-50,在识别不常见图像任务中的性能远超ResNet。
虽然CLIP在识别常见对象时往往表现良好,但在计算图像中对象数量等更抽象或更系统的任务,以及预测照片中最靠近车辆间的距离等更复杂任务上的表现不佳。在这两项任务上,zero-shot CLIP的效果也只比随机猜测好一点。
责任编辑:YYX
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
人工智能
+关注
关注
1809文章
49151浏览量
250613 -
OpenAI
+关注
关注
9文章
1211浏览量
8989
发布评论请先 登录
相关推荐
热点推荐
超小型Neuton机器学习模型, 在任何系统级芯片(SoC)上解锁边缘人工智能应用.
Neuton 是一家边缘AI 公司,致力于让机器 学习模型更易于使用。它创建的模型比竞争对手的框架小10 倍,速度也快10 倍,甚至可以在最先进的边缘设备上进行人工智能处理。在这篇博文中,我们将介绍
发表于 07-31 11:38
聚焦前沿,赋能AI教学!华清远见第32届全国高校人工智能师资班(多模态大模型与具身智能)圆满落幕!
2025年7月21日至25日,由华清远见教育科技集团倾力打造的第32届“全国高校人工智能师资培训班(多模态大模型与具身智能方向)”圆满落幕。

最新人工智能硬件培训AI 基础入门学习课程参考2025版(大模型篇)
在人工智能大模型重塑教育与社会发展的当下,无论是探索未来职业方向,还是更新技术储备,掌握大模型知识都已成为新时代的必修课。从职场上辅助工作的智能助手,到课堂用于学术研究的
发表于 07-04 11:10
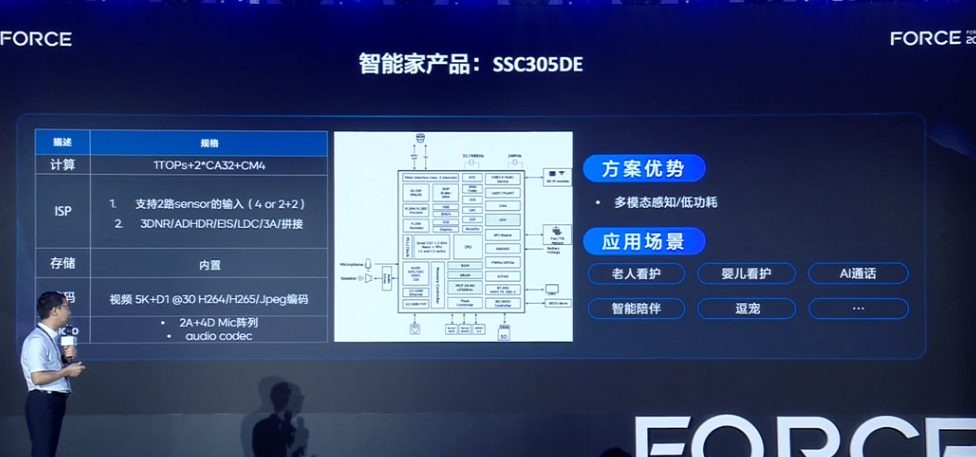
多模态感知+豆包大模型!家居端侧智能升级
电子发烧友网报道(文/李弯弯)日前,在火山引擎2025春季FORCE原动力大会上,星宸科技股份有限公司董事副总经理陈立敬谈到,在人工智能技术飞速发展的时代,多模态感知与大模型的融合成为
商汤日日新SenseNova融合模态大模型 国内首家获得最高评级的大模型
的大模型。 可信AI多模态大模型评估2025年1月启动,由中国信通院人工智能研究所牵头,依据由业界60余家单位共同编制的《
爱芯通元NPU适配Qwen2.5-VL-3B视觉多模态大模型
熟悉爱芯通元NPU的网友很清楚,从去年开始我们在端侧多模态大模型适配上一直处于主动紧跟的节奏。先后适配了国内最早开源的多模态大模MiniCP

我国生成式人工智能的发展现状与趋势
Intelligence,LI)时代,正在全面革新社会生产力。当前,大语言模型成为现代人工智能的基石,构筑起连接多模态的桥梁。2024年2月美国O
OpenAI提交新商标的申请
的新模型研发、拓展新的应用场景有关。 回顾 OpenAI 的发展历程,从最初发布 OpenAI gym,到后来推出 ChatGPT,再到不断迭代 GPT 系列
亥步多模态医疗大模型发布:人工智能引领医疗新纪元
当下,人工智能(AI)正以不可阻挡之势渗透到各行各业,包括医疗行业。12月14日,2024中国医学人工智能大会的召开。会上,一款名为“亥步”的多模态医疗大
AI看点:OpenAI 世界最贵大模型 阿里将推出人工智能电商工具
给大家带来一些最新的人工智能信息,希望对大家有用。 OpenAI发布满血版ChatGPT Pro OpenAI隆重推出了备受期待的“满血版”ChatGPT Pro。这一新版本基于全新的
嵌入式和人工智能究竟是什么关系?
嵌入式和人工智能究竟是什么关系?
嵌入式系统是一种特殊的系统,它通常被嵌入到其他设备或机器中,以实现特定功能。嵌入式系统具有非常强的适应性和灵活性,能够根据用户需求进行定制化设计。它
发表于 11-14 16:39

Meta发布多模态LLAMA 3.2人工智能模型
Meta Platforms近日宣布了一项重要技术突破,成功推出了多模态LLAMA 3.2人工智能模型。这一创新
OpenAI与Anthropic新模型将受美政府评估
近日,美国政府宣布了一项重要合作,旨在加强人工智能安全监管。根据协议,OpenAI与Anthropic两大AI领军企业同意,在推出新的AI模型
云知声推出山海多模态大模型
在人工智能技术的浩瀚星海中,多模态交互技术正成为引领未来的新航标。继OpenAI的GPT-4o掀起滔天巨浪后,云知声以创新之姿,推出了其匠心





 工商网监
工商网监
评论